| CPC G06F 40/289 (2020.01) [G06F 40/205 (2020.01); G06F 40/47 (2020.01); G06F 40/51 (2020.01)] | 22 Claims |
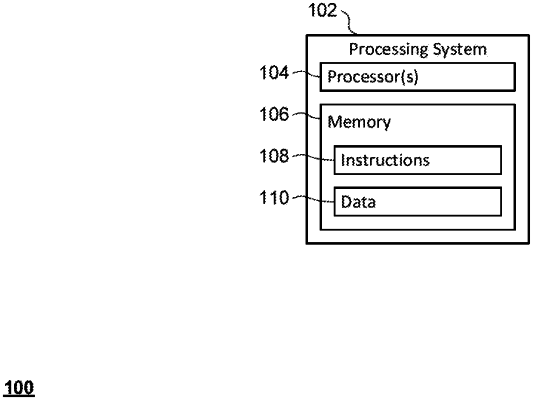
|
1. A method of training a neural network, comprising:
generating, by one or more processors of a processing system, for each given synthetic sentence pair of a plurality of synthetic sentence pairs, each given synthetic sentence pair comprising an original passage of text and a modified passage of text:
a first training signal of a plurality of training signals based on whether the given synthetic sentence pair was generated using backtranslation; and
one or more second training signals of the plurality of training signals based on a prediction from a textual entailment model regarding a likelihood that the modified passage of text of the given synthetic sentence pair entails or contradicts the original passage of text of the given synthetic sentence pair;
pretraining, by the one or more processors, the neural network to predict, for each given synthetic sentence pair of the plurality of synthetic sentence pairs, the plurality of training signals for the given synthetic sentence pair; and
fine-tuning, by the one or more processors, the neural network to predict, for each given human-graded sentence pair of a plurality of human-graded sentence pairs, a grade allocated by a human grader to the given human-graded sentence pair.
|