| CPC G06F 21/6254 (2013.01) [G06F 18/23 (2023.01); G06N 5/01 (2023.01)] | 17 Claims |
|
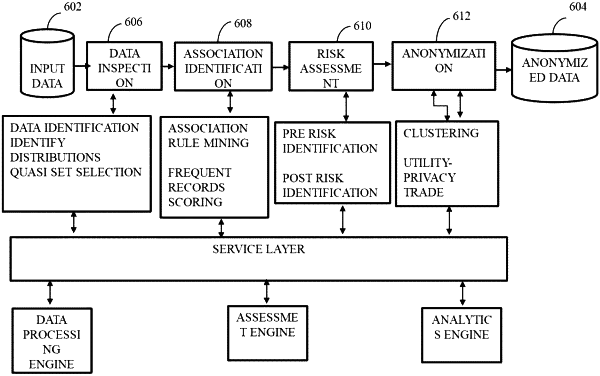
1. A processor implemented method for risk aware data anonymization, comprising:
obtaining a dataset comprising a plurality of records for anonymization, the plurality of records comprising a plurality of attributes, via one or more hardware processors;
identifying a first set of properties and a second set of properties of the plurality of records, via the one or more hardware processors, wherein the first set of properties is associated with metadata of the plurality of records, and the second set of properties defines generalization of the attributes of the plurality of records;
identifying, via the one or more hardware processors, one or more sensitive attributes, personal identifiable information (PII) and quasi-identifiers set associated with the plurality of attributes;
identifying, using one or more association rule mining techniques, a plurality of patterns in a subset of the dataset associated with the quasi-identifier set, via the one or more hardware processors, each of the plurality of patterns comprises a combination of attribute values associated with the plurality of attributes, the plurality of patterns identified based on a frequency of pattern occurrence in the plurality of records;
computing, via the one or more hardware processors, a record score associated with each record of the plurality of records based on a pattern associated with the record, wherein the record score associated with the record is indicative of risk-level associated with the record, and wherein the record score associated with the record is determined based on a support metric and a confidence metric associated with the record;
performing, based on the record score and an attribute proportion value associated with the plurality of attributes of the record, via the one or more hardware processors, a first level of risk assessment for the plurality of records to identify a set of risky records from amongst the plurality of records, the attribute proportion value associated with an attribute is indicative of proportion of the attribute in plurality of records;
classifying, via the one or more hardware processors, the set of risky records into a set of levels indicative of a severity of risk based on the one or more sensitive attributes associated with each of the set of risky records;
systematically applying a pattern-based K-Anonymization (PBKA) to the set of risky records and a set of remaining records from amongst the plurality of records using a greedy model, via the one or more hardware processors, wherein applying the PBKA comprises:
clustering the set of risky records and the set of remaining records to obtain a plurality of clusters, and
for each cluster of the plurality of clusters, forming a plurality of m-sets by mapping at least k records from amongst the plurality of records to a pattern from amongst the plurality of patterns based on the generalized information loss incurred;
computing, via the one or more hardware processors, a diversity metric for each m-set of the plurality of the m-sets, wherein the diversity metric is indicative of a distribution of the one or more sensitive attributes in the m-sets, and wherein the diversity metric of an m-set from amongst the plurality of m-sets is proportional to a distribution of unique sensitive attributes from amongst the one or more sensitive attributes in the dataset and a number of unique values in the m-set, and inversely proportional to size of the m-set;
computing, via the one or more hardware processors, a post-risk score indicative of a second level of risk assessment, wherein the post-risk score is computed as a total percentage of m-sets having a diversity metric greater than a threshold and the set of risky records being part of the diverse sets, wherein performing the second level of risk assessment comprises:
determining, from amongst the plurality of m-sets, a set of m-sets having the diversity metric greater than a predefined threshold value to obtain a plurality of diverse sets, and
determining whether the set of risky records belong to the plurality of diverse sets and a total predefined percentage of the sets are diverse.
|