| CPC G06F 16/3344 (2019.01) [G06F 16/367 (2019.01); G06F 18/214 (2023.01); G06F 40/205 (2020.01); G06F 40/284 (2020.01); G06N 20/00 (2019.01); G06F 16/36 (2019.01); G06F 18/10 (2023.01); G06F 40/211 (2020.01); G06F 40/279 (2020.01); G06F 40/295 (2020.01)] | 15 Claims |
|
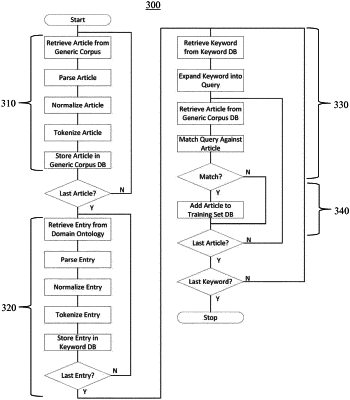
1. A method for generating a domain-specific training set, comprising:
generating a generic corpus comprising a plurality of tokenized documents obtained from one or more sources, comprising: (i) parsing a document retrieved from the generic corpus or from another source of documents; (ii) preprocessing the parsed document; (iii) tokenizing the preprocessed document; and (iv) storing the tokenized document in the generic corpus;
generating an ontology database of tokenized entries, comprising: (i) parsing an ontology entry retrieved from an ontology; (ii) preprocessing the parsed entry; (iii) tokenizing the preprocessed entry; and (iv) storing the tokenized entry in the ontology database;
querying using one or more domain-specific tokenized entries from the ontology database, the tokenized documents in the generic corpus;
identifying, based on the query, a plurality of tokenized documents specific to the domain; and
storing in a training set database, the identified plurality of tokenized documents as a training set specific to the domain.
|