| CPC G06F 16/24545 (2019.01) [G06F 9/4881 (2013.01); G06F 16/24532 (2019.01); G06F 16/9024 (2019.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
receiving a graph query to be executed against a graph database that includes a set of vertices;
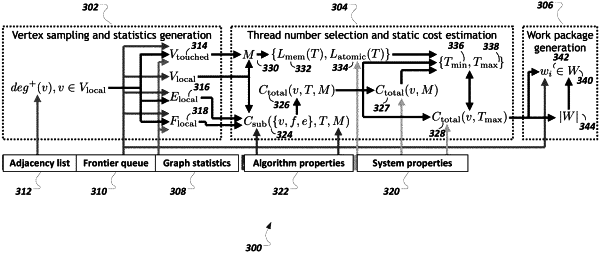
determining system properties of a system in which the graph query is to be executed;
determining algorithmic properties of at least one graph algorithm to be used to execute the graph query against the graph database;
determining graph data statistics for the graph database; and
for a first iteration of the graph query:
determining first graph traversal estimations for the first iteration of the graph query;
determining a first estimated cost model for the first iteration of the graph query based on the first graph traversal estimations;
determining first estimated thread boundaries for performing parallel execution of the first iteration of the graph query;
generating first work packages of a subset of the set of vertices to be processed during the execution of the first iteration of the graph query based on the first estimated cost model; and
providing the first work packages to a work package scheduler for scheduling the first work packages to execute the first iteration of the graph query.
|