| CPC G06F 16/2365 (2019.01) [G06F 21/6218 (2013.01)] | 3 Claims |
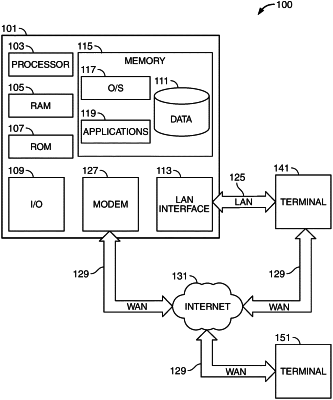
|
1. A method for extending a usable lifetime of a legacy database of an organization by converting documents stored on the legacy database from a format that is incompatible with a computer hardware processor in electronic communication with the legacy database into a format compatible with the computer hardware processor and using the converted documents to train a machine learning artificial intelligence (AI) system to auto-populate a newly requested document, the method comprising:
digitizing, using optical character recognition (OCR) run on the computer hardware processor, documents in a first format into a digital format;
wherein:
the first format is incompatible with the computer hardware processor; and
the documents are stored on the legacy database;
converting, using the computer hardware processor, the documents in the digital format into a second format;
wherein the second format is compatible with the computer hardware processor;
storing, using the computer hardware processor, the documents in the second format on the legacy database;
training, using a graphics processing unit (GPU) in electronic communication with the computer hardware processor, a machine learning AI system, using the documents stored in the second format in the legacy database;
wherein the machine learning AI system auto-populates new documents in the second format;
receiving a request, at the computer hardware processor, from an entity for a first document in the second format;
determining a confidence level, using the GPU, for completing the first document in the second format;
when the confidence level is above a pre-determined threshold, using the GPU to run the machine learning AI system to auto-populate the first document in the second format;
providing, using the computer hardware processor, the auto-populated first document in the second format to the entity for feedback;
receiving from the entity, at the computer hardware processor, the first document in corrected form indicating that there was a mistake in the auto-population of the first document;
storing, using the computer hardware processor, the first document in corrected form on the legacy database;
when the confidence level falls below the pre-determined threshold due to the mistake in the auto-population of the first document, updating the training of the machine learning AI system, using the GPU, to learn from the mistake;
receiving a request, at the computer hardware processor, from an entity for a second document in the second format;
determining, using the GPU, a confidence level for completing the second document;
when the confidence level for completing the second document is above the pre-determined threshold, using the GPU to run the machine learning AI system to auto-populate the second document;
providing, using the computer hardware processor, the auto-populated second document to the entity for feedback;
receiving, at the computer hardware processor, feedback from the entity that the second document is auto-populated correctly;
storing, using the computer hardware processor, the second document on the legacy database; and
updating, using the GPU, the machine learning AI system using the feedback that the second document is auto-populated correctly.
|