| CPC G10L 25/30 (2013.01) [G06N 3/04 (2013.01); G06N 3/045 (2023.01); G06N 3/048 (2023.01); G10L 13/06 (2013.01); G10H 2250/311 (2013.01)] | 20 Claims |
|
1. A neural network system implemented by one or more computers,
wherein the neural network system is configured to autoregressively generate an output sequence of audio data that comprises a respective audio sample at each of a plurality of time steps, and
wherein the neural network system comprises:
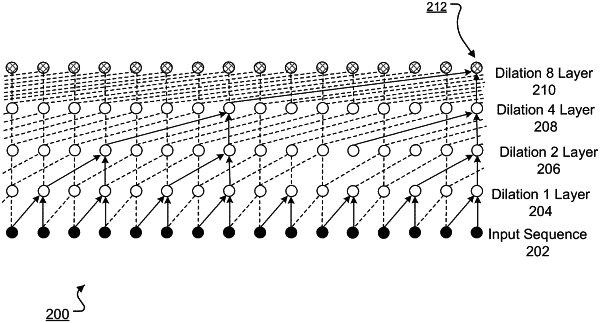
a convolutional subnetwork comprising one or more audio-processing convolutional neural network layers, wherein the convolutional subnetwork is configured to, for each of the plurality of time steps:
receive a current sequence of audio data that comprises the respective audio sample at each of multiple time steps that precede the time step in the output sequence, and
process the current sequence of audio data to generate an alternative representation for the time step;
wherein the neural network system is configured to process the alternative representations for the time steps to generate the output sequence of audio data.
|