| CPC G10L 15/16 (2013.01) [G10L 15/063 (2013.01); G10L 15/10 (2013.01); G10L 15/22 (2013.01); G10L 2015/0631 (2013.01); G10L 2015/227 (2013.01)] | 20 Claims |
|
1. A voice conversion learning device comprising:
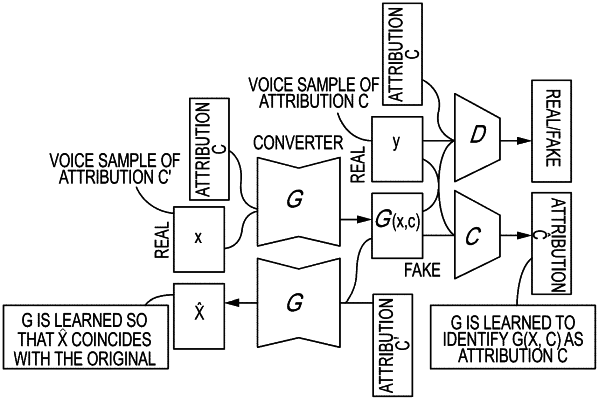
a learner configured to learn, on the basis of a sound feature value series for each of conversion-source voice signals with different attributions, and attribution codes indicating each attribution of the conversion-source voice signals, a converter configured to convert, for input of a sound feature value series and an attribution code, to a sound feature value series of a voice signal of an attribution indicated by the attribution code,
the learner learning the converter to minimize a value of a learning criterion represented using:
real voice similarity of a sound feature value series converted by the converter for input of any attribution code, the real voice similarity being associated with the any attribution code, the real voice similarity being identified a voice identifier for identifying, for input of an attribution code, whether a voice is a real voice with an attribution indicated by the attribution code or a synthetic voice,
attribution code similarity of a sound feature value series converted by the converter for input of any attribution code, the attribution code similarity being similarity to the any attribution code identified by an attribution identifier,
an error between a sound feature value series reconverted from the sound feature value series converted by the converter for input of an attribution code different from the attribution code of the conversion-source voice signal, the reconversion being done by the converter for input of the attribution code of the conversion-source voice signal, and the sound feature value series of the conversion-source voice signal, and
a distance between the sound feature value series converted by the converter for input of the attribution code of the conversion-source voice signal and the sound feature value series of the conversion-source voice signal, the learner learning the voice identifier to minimize a value of a learning criterion represented using:
real voice similarity of a sound feature value series converted by the converter for input of any attribution code, the real voice similarity being associated with the any attribution code, the real voice similarity being identified by the voice identifier for identifying, for input of an attribution code, whether a voice is a real voice with an attribution indicated by the attribution code or a synthetic voice, and
real voice similarity indicated by the attribution code of the sound feature value series of the conversion-source voice signal, the real voice similarity being identified by the voice identifier for input of the attribution code of the conversion-source voice signal, and
the learner learning the attribution identifier to minimize a value of a learning criterion represented using attribution code similarity of the sound feature value series of the conversion-source voice signal, the attribution code similarity being of the conversion-source voice signal identified by the attribution identifier.
|