| CPC G06F 40/295 (2020.01) [G10L 13/00 (2013.01); G10L 15/187 (2013.01)] | 15 Claims |
|
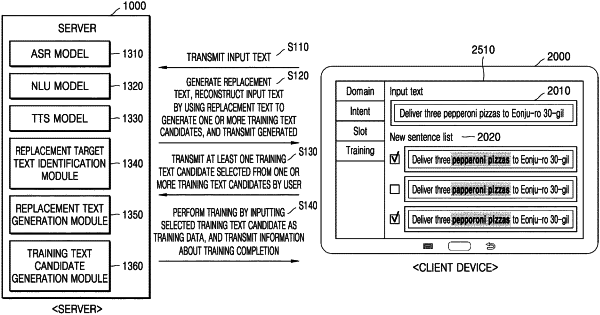
1. A method, performed by a server, of training a language model by using a text, the method comprising:
receiving, from a client device, an input text input by a user;
identifying a replacement target text to be replaced from among one or more words included in the input text;
generating a replacement text that is predicted to be uttered for the identified replacement target text by the user and has a phonetic similarity with the identified replacement target text;
generating one or more training text candidates by replacing, within the input text, the replacement target text with the generated replacement text; and
training a natural language understanding (NLU) model by using the input text and the one or more training text candidates as training data
wherein the generating of the replacement text comprises:
converting the replacement target text into a custom wave signal by using a personalized text-to-speech (TTS) model, wherein the personalized TTS model is an artificial intelligence model trained to generate a wave signal from a text by reflecting personalized characteristics including at least one of age, gender, region, dialect, intonation, and pronunciation of the user;
outputting the custom wave signal; and
generating the replacement text by converting the custom wave signal into an output text using an automatic speech recognition (ASR) model.
|