| CPC G10L 15/1815 (2013.01) [G06Q 30/0277 (2013.01); G10L 15/04 (2013.01); G10L 15/16 (2013.01)] | 20 Claims |
|
1. A system, comprising:
one or more processors; and
one or more memories storing computer-executable instructions that, when executed with the one or more processors, cause the system to at least:
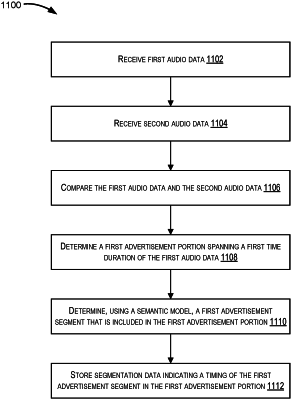
receive a first podcast file corresponding to a first version of an audio file, the first podcast file comprising first audio data, the first podcast file selected by a user;
receive a second podcast file corresponding to a second version of the audio file, the second podcast file comprising second audio data;
generate a first transcript of the first podcast file;
generate a second transcript of the second podcast file;
compare the first podcast file and the second podcast file by at least:
comparing the first audio data and the second audio data; and
comparing the first transcript and the second transcript;
determine, based at least in part on the comparison of the first podcast file and the second podcast file, a first advertisement portion spanning a first time duration of the first audio data and a second advertisement portion spanning a second time duration of the second audio data, the second advertisement portion being included in the second audio data in lieu of the first advertisement portion in the first audio data;
determine text data from the first transcript, the text data corresponding to the first time duration;
determine, by using a trained semantic model, an advertisement segment that is included in the first advertisement portion, wherein an input to the trained semantic model comprises the text data; and
store segmentation data corresponding to the first podcast file, the segmentation data indicating the first time duration and a timing of the advertisement segment in the first advertisement portion.
|