| CPC G10L 15/16 (2013.01) [G10L 15/063 (2013.01); G10L 15/22 (2013.01); G10L 2015/223 (2013.01)] | 18 Claims |
|
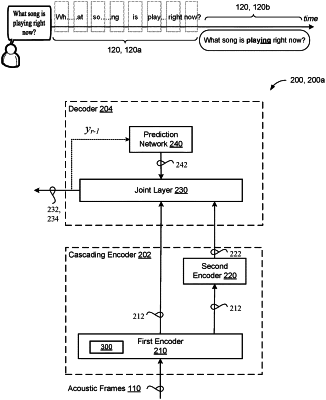
1. A system comprising data processing hardware and memory hardware in communication with the data processing hardware and storing instructions that when executed on the data processing hardware causes the data processing hardware to perform operations that comprise implementing an automated speech recognition (ASR) model, the ASR model comprising:
a causal encoder comprising a stack of causal encoder layers, the causal encoder configured to:
receive, as input, a sequence of acoustic frames; and
generate, at each of a plurality of output steps, a first higher order feature representation for a corresponding acoustic frame in the sequence of acoustic frames; and
a decoder configured to:
receive, as input, the first higher order feature representation generated by the causal encoder at each of the plurality of output steps; and
generate, at each of the plurality of output steps, a first probability distribution over possible speech recognition hypotheses,
wherein each causal encoder layer in the stack of causal encoder layers includes a Recurrent Neural Network (RNN) Attention-Performer module that applies linear attention,
wherein, during pre-training of the ASR model, each causal encoder layer comprises:
a first feedforward module;
a convolution module;
a multi-head attention module;
a second feedforward module; and
a layernorm module.
|