| CPC G10L 15/063 (2013.01) [G10L 2015/0635 (2013.01)] | 20 Claims |
|
1. A computer-implemented method for training a conversational recommendation system for generating an output, having a high play-probability, based on a minimal number of iterations of conversation, comprising:
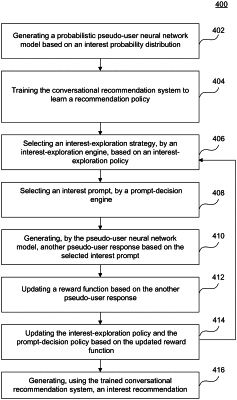
generating, by at least one computer processor, a probabilistic pseudo-user neural network model based on at least one interest probability distribution corresponding to a pseudo-user profile;
training, using the probabilistic pseudo-user neural network model, the conversational recommendation system to learn a recommendation policy, wherein the conversational recommendation system comprises an interest-exploration engine and a prompt-decision engine, and wherein the training includes performing one or more iterations of an iterative learning process, including:
selecting, by the interest-exploration engine, an interest-exploration strategy based on one or more of the following: an interest-exploration policy, an earlier pseudo-user response generated by the probabilistic pseudo-user neural network model, content data, and pseudo-user interaction history;
selecting, by the prompt-decision engine, an interest prompt based on a prompt-decision policy and the selected interest-exploration strategy;
generating, by the probabilistic pseudo-user neural network model, another pseudo-user response based on the selected interest prompt;
updating a reward function, corresponding to the interest-exploration engine and the prompt-decision engine, based on the another pseudo-user response; and
updating, using a reinforcement-learning method, the interest-exploration policy and the prompt-decision policy based on at least the updated reward function; and
generating, using the trained conversational recommendation system, a real-time recommendation having the high play-probability based on the minimal number of iterations of conversation between a user and the trained conversational recommendation system.
|