| CPC G10L 13/04 (2013.01) [G10L 13/10 (2013.01); G06V 40/10 (2022.01)] | 19 Claims |
|
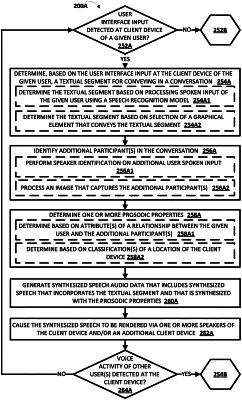
1. A method implemented by one or more processors, the method comprising:
detecting, via one or more microphones of a client device of a given user, spoken input of the given user;
determining, based on processing the spoken input of the given user, a textual segment for conveying in a conversation in which the given user is a participant;
identifying an additional participant in the conversation, the additional participant being in addition to the given user, and the additional participant being physically located in an environment with the given user;
determining at least one attribute of a relationship between the given user and the additional participant;
determining, based on the at least one attribute of the relationship between the given user and the additional participant, a given set of one or more prosodic properties, wherein the given set of the one or more prosodic properties is a first set of the one or more prosodic properties in response to determining the at least one attribute of the relationship between the given user and the additional participant is a first attribute, and wherein the given set of the one or more prosodic properties is a second set of the one or more prosodic properties in response to determining the at least one attribute of the relationship between the given user and the additional participant is a second attribute;
generating synthesized speech audio data that includes synthesized speech that incorporates the textual segment and that is synthesized with the given set of the one or more prosodic properties, wherein generating the synthesized speech audio data comprises synthesizing the synthesized speech with the given set of the one or more prosodic properties responsive to determining the given set of the one or more prosodic properties based on the attribute of the relationship between the given user and the additional participant; and
causing the synthesized speech to be rendered via one or more speakers of the client device and/or an additional client device, wherein the rendered synthesized speech is audibly perceptible to the additional participant.
|