| CPC G10H 1/0008 (2013.01) [A63F 13/54 (2014.09); G10H 2220/135 (2013.01); G10H 2250/235 (2013.01); G10H 2250/311 (2013.01)] | 13 Claims |
|
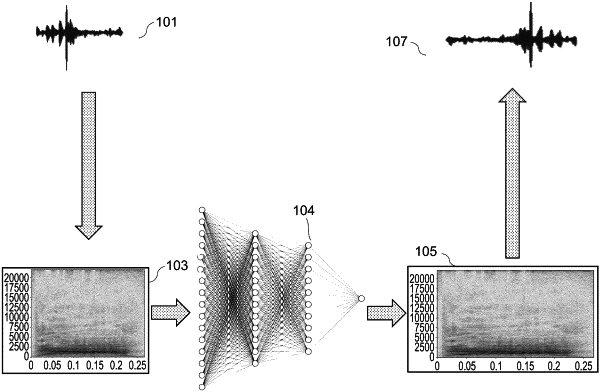
1. A method of generating audio assets, comprising the steps of:
receiving an input audio asset having a first duration,
generating an input image representative of the input audio asset,
training a generative model on the input image and implementing the trained generative model to generate an output image representative of an output audio asset having a second duration different to the first duration, and
generating the output audio asset based on the output image,
wherein the input image and output image each comprise an axis representative of time duration, and the step of generating an output image comprises retargeting the input image along the axis representative of time duration, and
wherein the output image has a larger dimension along the axis representative of time duration than the input image.
|
|
9. A non-transitory computer-readable medium having stored thereon a computer program comprising computer-implemented instructions that, when run on a computer, cause the computer to implement a method of generating audio assets, comprising the steps of:
receiving an input audio asset having a first duration,
generating an input image representative of the input audio asset,
training a generative model on the input image and implementing the trained generative model to generate an output image representative of an output audio asset having a second duration different to the first duration, and
generating the output audio asset based on the output image,
wherein the input image and output image each comprise an axis representative of time duration, and the step of generating an output image comprises retargeting the input image along the axis representative of time duration, and
wherein the output image has a larger dimension along the axis representative of time duration than the input image.
|
|
10. A system for generating audio assets, the system comprising:
an asset input unit configured to receive an input audio asset having a first duration, and to convert the input audio asset into an input image,
an image generation unit configured to implement a generative model to generate one or more output images based on the input image, the output image representing an output audio asset having a second duration different to the first duration, and
an asset output unit configured to generate an output audio asset based on the output image,
wherein the input image and output image each comprise an axis representative of time duration, and the step of generating an output image comprises retargeting the input image along the axis representative of time duration, and
wherein the output image has a larger dimension along the axis representative of time duration than the input image.
|