| CPC G06V 30/418 (2022.01) [G06F 16/353 (2019.01); G06F 16/355 (2019.01); G06N 3/04 (2013.01)] | 20 Claims |
|
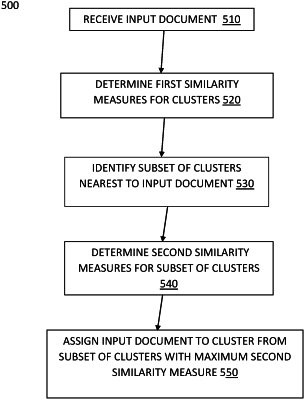
1. A computer-implemented method for document clusterization, comprising:
receiving an input document;
determining, by evaluating a first document similarity function, a first plurality of similarity measures, wherein each similarity measure of the first plurality of similarity measures reflects a degree of similarity between the input document and a corresponding cluster of documents of a plurality of clusters of documents, wherein a first likelihood of the first document similarity function to yield a false negative result exceeds a second likelihood of the first document similarity function to yield a false positive result;
based on the plurality of similarity measures, determining that the input document belongs to a subset comprising two or more adjacent clusters of the plurality of clusters of documents, wherein a distance between centroids of the two or more adjacent clusters is less than a predefined separation distance;
determining, by evaluating a second document similarity function that is different from the first document similarity function, a second plurality of similarity measures, wherein each similarity measure of the second plurality of similarity measures reflects a degree of similarity between the input document and a corresponding cluster of documents of the subset of the plurality of clusters of documents, and wherein the first document similarity function is based on a first number of attributes of the input document, the second document similarity function is based on a second number of attributes of the input document, the second number exceeding the first number;
associating the input document with a cluster of documents associated with a maximum similarity measure of the second plurality of similarity measures.
|