| CPC G06T 9/00 (2013.01) [G06T 3/4084 (2013.01); G06T 7/168 (2017.01); G06T 7/60 (2013.01); G06T 7/73 (2017.01); G06T 2207/10028 (2013.01); G06T 2207/20064 (2013.01)] | 20 Claims |
|
1. A method comprising:
accessing, by a point cloud compression system, an input point cloud dataset comprising a plurality of data points and representative of a point cloud comprising a plurality of points, each data point of the plurality of data points corresponding to a single point of the plurality of points and including a respective set of values corresponding to each attribute in a set of attributes that includes a first attribute and a second attribute for each point of the plurality of points;
identifying, by the point cloud compression system, a first attribute dataset and a second attribute dataset within the input point cloud dataset, each data point of the first attribute dataset corresponding to the first attribute from each of the respective sets of values and to a single point of the plurality of points, and each data point of the second attribute dataset corresponding to the second attribute from each of the respective sets of values and to a single point of the plurality of points;
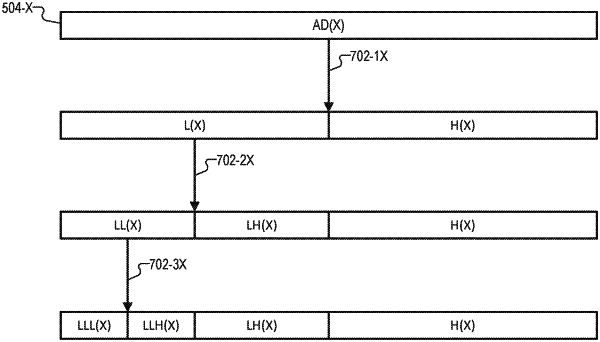
generating, by the point cloud compression system and based on an application of a transform algorithm to the first attribute dataset, a first low-frequency component and a first high-frequency component of the first attribute dataset;
generating, by the point cloud compression system and based on an application of the transform algorithm to the second attribute dataset, a second low-frequency component and a second high-frequency component of the second attribute dataset; and
generating, by the point cloud compression system, an output point cloud dataset that prioritizes both the first and second low-frequency components above both the first and second high-frequency components.
|