| CPC G06Q 30/0202 (2013.01) [G06N 20/00 (2019.01)] | 20 Claims |
|
1. A computerized method for quantifying or analyzing data assets that is executed by one or more processing devices and stored as computing instructions on one or more non-transitory storage devices, the method comprising:
providing, via execution of the computing instructions by the one or more processing devices, an asset evaluation system that is configured to generate one or more data asset predictions for data assets associated with an entity;
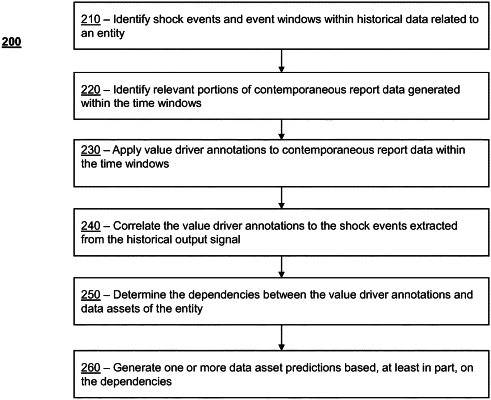
receiving, by an event analysis module of the asset evaluation system stored on the one or more non-transitory storage devices, historical data relating to the entity;
detecting, by execution of the event analysis module on the one or more processing devices, at least one shock event corresponding to the entity based on an analysis of the historical data;
identifying, by the one or more processing devices, an event window corresponding to the at least one shock event;
accessing, by the one or more processing devices, contemporaneous report data generated or published during the event window;
electronically analyzing, using a relevance model of the asset evaluation system that is executed by the one or more processing devices, the contemporaneous report data to identify portions of the contemporaneous report data that are relevant to the entity, wherein:
the relevance model comprises a learning model that is pre-trained to determine whether textual content generated or published during the event window is relevant to the entity;
the relevance model analyzes the textual content generated or published during the event window to identify the portions of the textual content that are relevant to the entity and other portions of the textual content that are not relevant to the entity; and
the relevance model assigns relevance labels to the portions of textual content that are determined to be relevant to the entity and assigns irrelevant labels to the other portions of the textual content;
assigning, by the one or more processing devices, one or more value driver annotations to the portions of the contemporaneous report data identified as being relevant to the entity, each of the one or more value driver annotations corresponding to a label that identifies a value driving factor that contributed to the at least one shock event;
determining, by the one or more processing devices, a value for each of the one or more value driver annotations; and
electronically generating, by the one or more processing devices, the one or more data asset predictions based, at least in part, on the value for each of the one or more value driver annotations.
|