| CPC G06N 3/08 (2013.01) [G06F 9/3001 (2013.01); G06F 9/30032 (2013.01); G06F 9/30036 (2013.01); G06F 17/11 (2013.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01); G06N 20/00 (2019.01)] | 17 Claims |
|
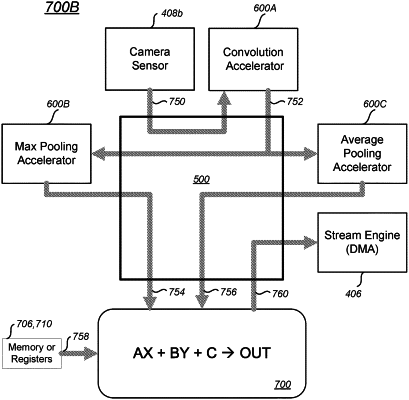
1. An integrated circuit, comprising:
a plurality of convolutional accelerators;
an arithmetic circuit having a plurality of inputs; and
a reconfigurable stream switch coupled to the plurality of convolutional accelerators and to the arithmetic circuit, wherein,
the reconfigurable stream switch, in operation,
streams data between convolutional accelerators of the plurality of convolutional accelerators;
streams data between convolutional accelerators of the plurality of convolutional accelerators and inputs of the plurality of inputs of the arithmetic circuit; and
streams an output of the arithmetic circuit, and
the arithmetic circuit, in operation, generates the output according to AX+BY+C, wherein:
A, B and Care vector or scalar constants; and
X and Y are data streams streamed to the arithmetic circuit through the reconfigurable stream switch, wherein, the plurality of convolutional accelerators includes:
a first convolution accelerator, which, in operation, performs a max pooling operation;
a second convolution accelerator, which, in operation, perform an average pooling operation; and
a third convolutional accelerator, which, in operation, convolves image sensor data streamed through the reconfigurable stream switch to produce a stack of kernel maps, wherein, in operation:
the stack of kernel maps is streamed through the reconfigurable stream switch to the first convolution accelerator and to the second convolution accelerator;
max pool data from the first convolutional accelerator is streamed through the reconfigurable stream switch as input data to the arithmetic circuit;
average pool data from the second convolutional accelerator is streamed through the reconfigurable stream switch as input data to the arithmetic circuit;
the arithmetic circuit performs a max-average pooling operation; and
max-average pool data from the arithmetic circuit is streamed through the reconfigurable stream switch.
|