| CPC G06N 3/063 (2013.01) [G06F 1/03 (2013.01); G06F 5/01 (2013.01); G06F 7/5443 (2013.01); G06F 9/30098 (2013.01); G06F 9/30145 (2013.01); G06F 17/10 (2013.01); G06F 17/16 (2013.01); G06N 3/048 (2023.01); G06N 3/06 (2013.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01); G06N 5/04 (2013.01); G06N 5/046 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
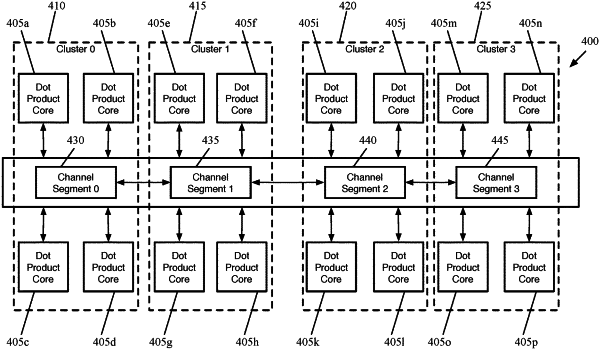
1. For a neural network inference circuit, a method for executing a neural network that comprises a plurality of computation nodes, each of a set of the computation nodes comprising a dot product of input values and weight values, the method comprising:
to compute a particular computation node:
at each respective dot product core circuit of a plurality of dot product core circuits of the neural network inference circuit, computing a respective partial dot product using a respective set of input values and a respective set of weight values stored in a respective set of memories of the respective dot product core circuit; and
at a bus of the neural network inference circuit that comprises a plurality of aggregation circuits, combining the partial dot products computed by the plurality of dot product core circuits to compute the dot product for the particular computation node.
|