| CPC G06N 20/00 (2019.01) [G06F 16/24573 (2019.01); G06F 16/24578 (2019.01)] | 20 Claims |
|
1. A computer-implemented method of automatically selecting data for machine learning datasets, the method comprising:
using a number of processors to perform:
receiving an input dataset;
receiving user-specified data quality metrics;
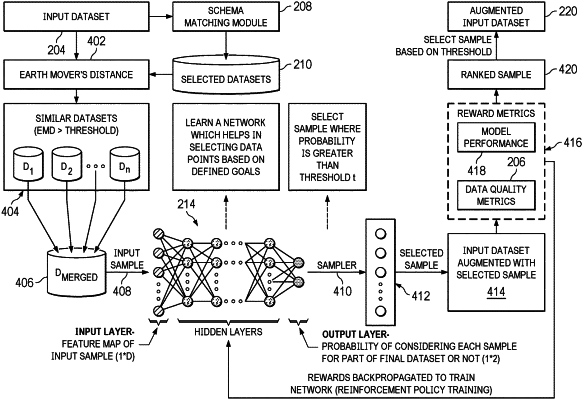
matching the input dataset to a first subset of candidate datasets in a repository according to schema characteristics;
selecting a second subset of candidate datasets from the first subset of candidate datasets having a distance from the input dataset above a specified threshold;
merging the second subset of candidate datasets into a merged dataset;
identifying top ranked samples from the merged dataset above a specified second threshold based on the user-specified data quality metrics wherein the identification of top ranked samples from the merged dataset comprises:
feeding samples from the merged dataset into a reinforcement machine learning model that outputs a probability of selecting each sample for a final dataset;
selecting samples from among the samples that have a probability of being selected greater than a specified fourth threshold; and
augmenting the input dataset with the selected samples; and
returning the input dataset augmented with the top ranked samples to a user.
|