| CPC G06F 40/58 (2020.01) [G06F 40/169 (2020.01); G06F 40/279 (2020.01); G06F 40/30 (2020.01); G06F 40/45 (2020.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A data processing system comprising:
a processor; and
a machine-readable medium storing executable instructions that, when executed, cause the processor to perform operations comprising:
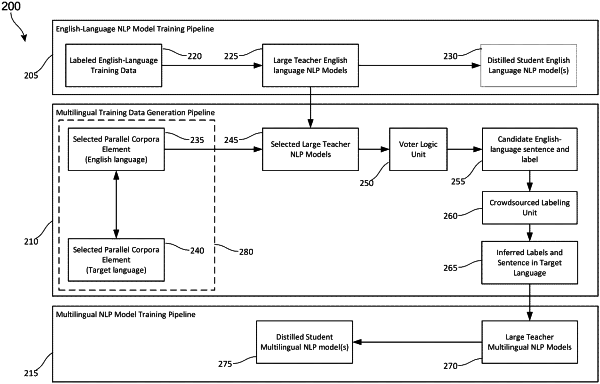
obtaining a corpus comprising a plurality of first content items and a plurality of second content items, wherein the plurality of first content items comprise English-language textual content, and the plurality of second content items comprise translations of the first content items in one or more non-English target languages; and repeatedly
selecting a first content item from the plurality of first content items;
generating a plurality of candidate labels for the first content item by analyzing the first content item with a plurality of first natural language processing (NLP) models, the plurality of first NLP models including only English-language NLP models trained to analyze an English-language input and to generate a candidate label output;
determining whether a majority of the first NLP models agree that one or more first candidate labels among the plurality of the candidate labels generated by the first NLP models represent context of the first content item consisting of the English-language textual content;
upon determining the majority of the first NLP models agree that the one or more first candidate labels represent context of the first content item consisting of the English-language textual content, sending the one or more first candidate labels and the first content item to a crowdsourced work platform for label verification by a plurality of reviewers to receive an indication that the one or more first candidate labels accurately represent the first content item, responsive to a threshold number of reviewers determining that the one or more first candidate labels accurately represent the first content item; and
determining a percentage of English-language elements that were determined to be labeled correctly via the label verification;
when determining the percentage of the English-language elements does not satisfy a correct labeling threshold, performing at least one of removing one or more low performing first NLP models, adding one or more additional first NLP models, or selecting data from a different corpus from the plurality of first content items and the plurality of second content items;
when determining the percentage of the English-language elements satisfies the correct labeling threshold,
(1) setting a set of the one or more first candidate labels with the first content item passed via the label verification as test data for testing a pretrained multilingual NLP model, and
(2) generating first training data for fine tuning the pretrained multilingual NLP model by repeatedly:
selecting another first content item from the plurality of first content items or the different corpus;
generating a plurality of candidate labels for the other first content item by analyzing the other first content item with the plurality of first NLP models;
determining whether a majority of the first NLP models agree that one or more other first candidate labels among the plurality of the candidate labels generated by the first NLP models for the other first content item represent context of the other first content item consisting of the English-language textual content; and
upon determining the majority of the first NLP models agree that the one or more other first candidate labels represent context of the first content item consisting of the English-language textual content, setting the one or more other first candidate labels with the other first content item in the first training data;
generating second training data for fine tuning the pretrained multilingual NLP model by associating the one or more other first candidate labels with a second content item of the plurality of second content items; and
training the pretrained multilingual NLP model with the first training data and the second training data to fine tune training of the pretrained multilingual NLP model with respect to English and a respective non-English target language associated with the second content item.
|