| CPC G06F 3/013 (2013.01) [A63F 13/358 (2014.09); A63F 13/52 (2014.09); G06F 3/012 (2013.01); G06F 3/017 (2013.01); G06T 1/60 (2013.01); A63F 2300/8082 (2013.01)] | 15 Claims |
|
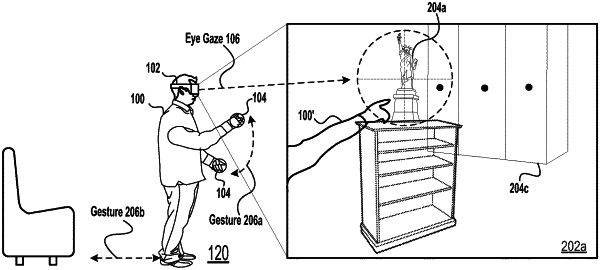
1. A method for fetching graphics data for rendering a scene presented on a display, comprising:
receiving gaze information for eyes of a user while the user is interacting with the scene;
tracking gestures of the user while the user is interacting with the scene;
identifying a content item in the scene as being a potential focus of interactivity by the user, the content item is a virtual object that is configured for interaction in the scene, wherein said identifying the content item in the scene is assisted by a machine learning model;
processing the gaze information and the gestures of the user to generate a prediction of interaction with the content item by the user, the prediction of interaction uses a behavior model and said machine learning model to identify relationships between the gaze information of the user while the user is interacting in the scene and the gestures of the user while the user is interacting in the scene to predict a likelihood of the user interacting with said content item;
processing a pre-fetching operation to access and load the graphics data associated with said content item into system memory based on said predicted likelihood in anticipation of the user interacting with the content item; and
rendering the content item at an increased image quality in the scene using said pre-fetched graphics data in anticipation of the user interacting with the content item.
|