| CPC G06F 18/2178 (2023.01) [G06F 18/2115 (2023.01); G06F 18/2148 (2023.01); G06F 18/2433 (2023.01); G06N 20/20 (2019.01)] | 20 Claims |
|
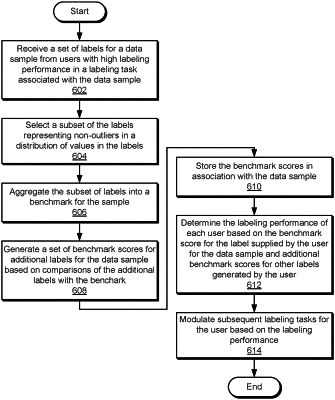
1. A computer-implemented method for evaluating labeled data, comprising:
selecting, based on a distribution of label values included in a set of labels for a data sample, a subset of at least two different labels, wherein each label of the subset is selected based on a corresponding label value that is a non-outlier in the distribution of label values, and wherein the subset of the at least two different labels is further selected based on high consensus among a first group of users with labeling performance that exceeds a threshold and low consensus among a second group of users with labeling performance that falls below the threshold;
receiving an additional label for the data sample;
determining a benchmark for the data sample based on the subset of the at least two different labels;
generating, based on one or more comparisons of the additional label with the benchmark, a benchmark score for the additional label; and
generating a set of performance metrics for labeling the data sample based on the benchmark score.
|