| CPC G06F 16/9532 (2019.01) [G06F 40/284 (2020.01); G06F 40/289 (2020.01); G06F 40/40 (2020.01)] | 16 Claims |
|
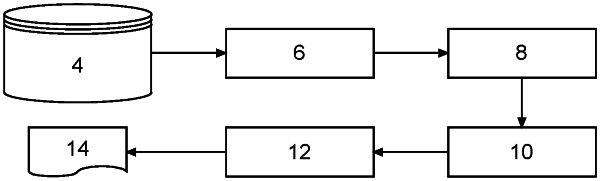
1. A computer implemented method for improving a search engine comprising:
a. receiving a text corpus;
b. determining a list of n-gram candidates, each being a series of consecutive words of said text corpus, a number of said consecutive words within said series being an integer n superior or equal to two;
c. modifying at least partially said text corpus based on said list of n-gram candidates;
d. performing a machine learning embedding on the text corpus at least partially modified in step c;
e. for each element in said list of n-gram candidates, computing a score based on the embedding of said element and the embeddings of the words making up said element; and
f. adding one or more of the n-gram candidates to a search engine queries items list based on their respective scores,
wherein step c further includes:
parsing the text corpus with a list of n-gram candidates of step b, and each time a series of consecutive words of said text corpus make up a given element of said list of n-gram candidates, determining whether one or more words consecutive to said series of consecutive words of said text corpus make up a different element of said list of n-gram candidates with one or more of endmost words of said series of consecutive words of said text corpus, and, in such case, using a pseudo-random function parametrized by a number of times the series of words making up said given element has already been replaced by a token associated with a corresponding given element within the part of the text corpus already parsed to compute a value determining whether the series of consecutive words making up said given element should be tokenized as a single word token or not, and applying same processing to the series of consecutive words making up said different element.
|