| CPC G06F 16/65 (2019.01) [G10L 25/30 (2013.01); G10L 25/57 (2013.01)] | 18 Claims |
|
1. One or more non-transitory computer-readable media comprising computer-executable instructions that, when executed by one or more processors of a computer system, cause the computer system to perform operations comprising:
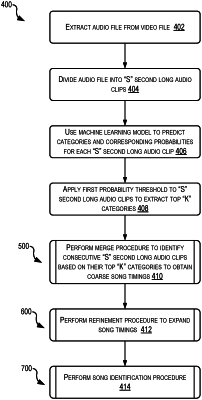
determining a plurality of audio clips based at least in part on an audio file corresponding to a video file;
training an audio neural network to generate a pre-trained audio neural network (PANN), wherein the training comprises training the PANN using an ontology comprising labeled audio categories and labeled sound clips, wherein the ontology comprises a hierarchical graph of sound categories, wherein training the audio neural network to generate the PANN comprises generating the PANN to receive an audio signal to output audio embeddings having attributes about the audio signal;
determining, for a first audio clip of the plurality of audio clips, and by inputting the first audio clip into the PANN:
a plurality of audio categories that correspond to a plurality of sounds; and
a plurality of probabilities associated with the plurality of audio categories, each probability indicating a probability that the first audio clip includes a sound represented by a respective audio category;
determining, for the first audio clip, a set of audio categories indicating likelihoods of audio classes being included in the first audio clip, the set of audio categories included in the plurality of audio categories, wherein determining the set of audio categories includes evaluating the first audio clip by applying a first probability threshold using a set of probabilities of the plurality of probabilities that correspond to the set of audio categories, each audio category of the set of audio categories being associated with a different audio class label of a set of audio class labels, wherein the determining comprises applying the first probability threshold to define a top predetermined number of categories with respect to a set of conditional rules defined in terms of class labels;
determining, for the first audio clip, that the first audio clip is part of a song by:
applying a second probability threshold using the set of probabilities; and
further evaluating the first audio clip according to one or more audio class conditional statements using the set of audio class labels associated with the set of audio categories of the first audio clip to refine the set of audio categories associated with the first audio clip; and
generating the song by:
combining the first audio clip with other audio clips of the plurality of audio clips to generate a coarse song beginning and a coarse song ending;
identifying a refined song beginning and a refined song ending using the plurality of audio categories; and
replacing the coarse song beginning and the coarse song ending with the refined song beginning and the refined song ending, respectively.
|