| CPC G06F 16/285 (2019.01) [G06F 18/2415 (2023.01)] | 20 Claims |
|
1. A method for fairness-aware data distillation for attribute classification, comprising:
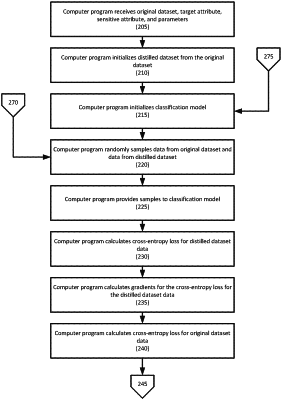
receiving, by a fairness-aware data distillation computer program executed by a computer processor, an original dataset and a sensitive attribute;
initializing, by the fairness-aware data distillation computer program, a distilled dataset from the original dataset;
initializing, by the fairness-aware data distillation computer program, a classification model executed by the computer processor;
sampling, by the fairness-aware data distillation computer program, original dataset data and an original dataset label from the original dataset, and distilled dataset data and a distilled dataset label from the distilled dataset;
providing, by the fairness-aware data distillation computer program, the sampled original dataset data from the original dataset to the classification model, resulting in an original dataset prediction probability that is received from the classification model;
providing, by the fairness-aware data distillation computer program, the sampled distilled dataset data from the distilled dataset to the classification model, resulting in a distilled dataset prediction probability that is received from the classification model;
calculating, by the fairness-aware data distillation computer program, a distilled dataset cross-entropy loss for the distilled dataset prediction probability and the distilled dataset label;
calculating, by the fairness-aware data distillation computer program, distilled dataset gradients for the distilled dataset cross-entropy loss;
calculating, by the fairness-aware data distillation computer program, a distance between the distilled dataset gradients and gradients for an original dataset total loss as a matching loss; and
updating, by the fairness-aware data distillation computer program, the distilled dataset with the matching loss for training the classification model to output a result.
|