| CPC G06F 16/24539 (2019.01) [G06F 16/24561 (2019.01)] | 12 Claims |
|
1. A computer-implemented method for optimizing query processing in a cloud database storage system using a best-effort cache population, the computer-implemented method comprising:
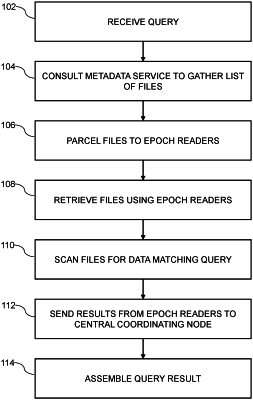
receiving, by a central coordinating node from a query source, a query of a dataset stored in the cloud database storage system, wherein the query comprises at least one query parameter, wherein the at least one query parameter comprises a time range;
transmitting, by the central coordinating node to a metadata service, one or more query parameters of the at least one query parameter, wherein the one or more transmitted query parameters comprises the time range;
receiving, by the central coordinating node from the metadata service, a list comprising a plurality of files related to the query, wherein each file of the plurality of files related to the query is selected from the time range;
distributing, by the central coordinating node to a plurality of processing nodes, the plurality of files related to the query, wherein each processing node of the plurality of processing nodes is assigned a corresponding subset of the plurality of files, and wherein each processing node of the plurality of processing nodes comprises a local storage cache of recently queried files and/or recently generated files of the cloud database storage system;
determining, by each of the plurality of processing nodes, whether the corresponding subset of the plurality of files is stored on the local storage cache;
if the corresponding subset of the plurality of files is not stored on the local storage cache:
retrieving, by each of the plurality of processing nodes, the corresponding subset of the plurality of files not stored on the local storage cache from the cloud database storage system;
storing, by each of the plurality of processing nodes, the retrieved corresponding subset of the plurality of files in a local random access memory corresponding to each of the plurality of processing nodes;
scanning, by each of the plurality of processing nodes, the corresponding subset of the plurality of files stored in the local random access memory for data matching the at least one query parameter to generate a subset of query results;
copying, concurrently with the scanning and using a separate processing thread from the scanning, the corresponding subset of the plurality of files stored in the local random access memory to the local storage cache;
determining that the scanning is complete;
determining if the copying is complete; and
if the copying is not complete:
abandoning the copying; and
discarding the subset of the plurality of files from the local random access memory;
if the corresponding subset of the plurality of files is stored on the local storage cache:
scanning, by each of the plurality of processing nodes, the corresponding subset of the plurality of files stored on the local storage cache for data matching the at least one query parameter to generate the subset of query results;
transmitting, from each of the plurality of processing nodes to the central coordinating node, the subset of query results;
aggregating, by the central coordinating node, each subset of query results from each of the plurality of processing nodes to generate a final query result; and
transmitting, by the central coordinating node to the query source, the final query result,
wherein the central coordinating node and each of the plurality of processing nodes comprise a processor and computer-readable memory.
|