| CPC G06F 40/30 (2020.01) [G06F 18/217 (2023.01); G06F 18/23 (2023.01); G06F 40/284 (2020.01); G06N 20/00 (2019.01); G06T 7/97 (2017.01); G06V 10/762 (2022.01); G06V 30/1916 (2022.01); G06V 30/268 (2022.01); G06V 30/274 (2022.01); G06V 30/40 (2022.01)] | 20 Claims |
|
1. A method comprising:
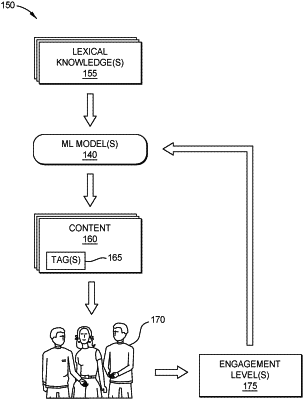
training a machine learning (ML) model to identify appropriate documents based on lexical knowledge of target groups of users, comprising:
generating a test lexical complexity score by processing a level of lexical knowledge of a test audience using the ML model;
determining test engagement of the test audience based on one or more documents assigned the test lexical complexity score, from a corpus of documents; and
refining the ML model based on the test engagement of the test audience in response to the one or more documents, comprising modifying one or more weights of the ML model to correlate lexical knowledge and lexical complexity with user engagement;
determining a lexical knowledge of a set of users;
selecting a first document of a plurality of documents by processing the determined lexical knowledge using the ML model, comprising determining that the first document is tagged with a lexical complexity score that matches output of the ML model;
facilitating presentation of the first document to the set of users;
determining a level of engagement of the set of users, comprising:
capturing audio of the set of users during the presentation of the first document; and
determining, based on the audio, a frequency of questions, from the set of users, relating to the presentation; and
upon determining that the level of engagement is below a predefined threshold, selecting a second document of the plurality of documents using the ML model.
|