| CPC H04R 25/507 (2013.01) [G06N 3/08 (2013.01); G10L 17/00 (2013.01); G10L 21/013 (2013.01); H04R 25/70 (2013.01); H04R 2225/43 (2013.01)] | 16 Claims |
|
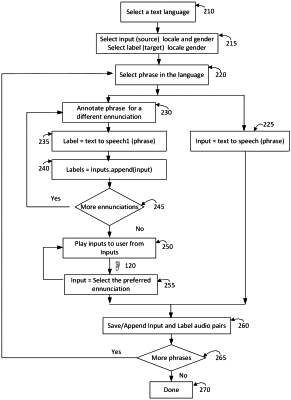
1. A method of computer processing detected speech to enhance intelligibility of the speech as heard by a hearing impaired listener using a first speech articulation transformational model, the method including the following steps:
(a) selecting input samples from a first speech articulation distribution guided by a second neural network model co-developed by the first model, and for each of the selected input samples, generating alternative articulations;
(b) during an interactive session, enabling the hearing impaired listener to hear, at a sound level appropriate to the hearing impaired listener, the alternative articulations for each of the selected input samples;
(c) selecting for each input sample at least a sample from the alternative articulations that includes an enhanced intelligibility speech preferred by the hearing impaired listener, whereby a plurality of preferred articulations is created;
(d) designating the plurality of preferred articulations as second speech articulation distribution data for the hearing impaired listener;
(e) creating a labeled dataset of corresponding pairs from the first speech articulation distribution and the second speech articulation distribution, the labeled dataset representing at least one learnable articulation pattern; and
(f) training the first model from the labeled dataset such that the first model in response to an unseen input from the first speech articulation distribution transforms at least one constituent feature of the unseen input to generate for the listener in real time an enhanced intelligibility output speech.
|