| CPC G16H 40/63 (2018.01) [G06F 16/355 (2019.01); G06F 16/358 (2019.01); G06F 18/2135 (2023.01); G16H 10/60 (2018.01); G16H 50/70 (2018.01)] | 13 Claims |
|
1. A patient cohort identification device comprising:
a computer having a display component and at least one user input device, the computer being in communication with a patient database storing patient data comprising values of features for patients in the patient database, the computer programmed to perform a patient cohort identification method including:
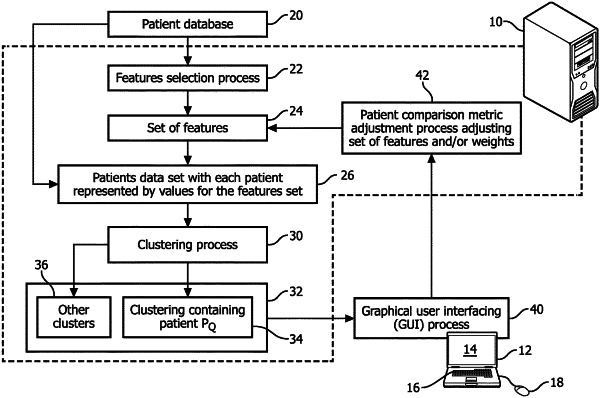
performing an automatic feature selection process on the patient data to select a set of features and automated clustering of patients of the patient database using a patient comparison metric dependent on the set of features, wherein the automatic feature selection process is an unsupervised feature selection process, and wherein the automated clustering comprises generating a plurality of clusters including at least a first cluster of patients of the patient database similar to a query patient and at least a second cluster of patients of the patient database dissimilar to a query patient;
performing at least one iteration of:
displaying, on the display component, information on a plurality of sample patients, the plurality of sample patients including (i) one or more patients from the first cluster who are similar to the query patient according to the automated clustering, and (ii) one or more patients from the second cluster who are dissimilar to the query patient according to the automated clustering;
receiving, via the at least one user input device, user-inputted comparison values comparing one or more of the plurality of sample patients with the query patient, wherein the user-inputted comparison values comprise a comparison of the query patient and the plurality of sample patients at a patient level rather than a feature level using the set of features, and comprise either: (i) a ranking of similarity of the plurality of sample patients relative to the query patient or (ii) a selection of one or more of plurality of patients most similar to the query patient;
adjusting the patient comparison metric to increase agreement between the user-inputted comparison values and comparison values computed by the patient comparison metric comparing the one or more sample patients with the query patient, wherein the adjusting including adjusting at least one of the set of features and feature weights of the patient comparison metric; and
repeating the automated clustering using the adjusted patient comparison metric; and
identifying a patient cohort for the query patient using the adjusted patient comparison metric produced by a last iteration of the last least one iteration.
|