| CPC G10L 19/032 (2013.01) [G10L 19/008 (2013.01); H04R 3/005 (2013.01); H04R 3/04 (2013.01); H04R 3/12 (2013.01); H04R 5/04 (2013.01); H04S 7/307 (2013.01); H04S 2420/11 (2013.01)] | 16 Claims |
|
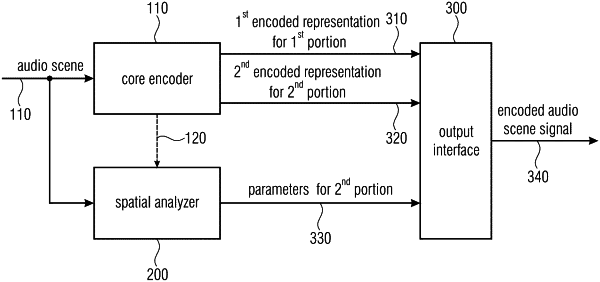
1. Audio scene encoder for encoding an audio scene, the audio scene comprising at least two component signals, the audio scene encoder comprising:
a core encoder for core encoding the at least two component signals, wherein the core encoder is configured to generate a first encoded representation for a first portion of the at least two component signals, and to generate a second encoded representation for a second portion of the at least two component signals;
a spatial analyzer for analyzing the audio scene comprising the at least two component signals to derive one or more spatial parameters or one or more spatial parameter sets for the second portion of the at least two component signals; and
an output interface for forming an encoded audio scene signal, the encoded audio scene signal comprising the first encoded representation for the first portion of the at least two component signals, the second encoded representation for the second portion of the at least two component signals, and the one or more spatial parameters or the one or more spatial parameter sets for the second portion of the at least two component signals,
wherein the core encoder is configured to generate the first encoded representation with a first frequency resolution and to generate the second encoded representation with a second frequency resolution, the second frequency resolution being lower than the first frequency resolution, from subsequent time frames from the at least two component signals, wherein a first time frame of the subsequent time frames is the first portion of the at least two component signals and a second time frame of the subsequent time frames is the second portion of the at least two component signals, or
wherein a border frequency between a first frequency subband of a time frame and a second frequency subband of the time frame coincides with a border between a scale factor band and an adjacent scale factor band or does not coincide with a border between the scale factor band and the adjacent scale factor band, wherein the scale factor band and the adjacent scale factor band are used by the core encoder, wherein the first frequency subband of the time frame is the first portion of the at least two component signals and the second frequency subband of the time frame is the second portion of the at least two component signals.
|