| CPC G10L 15/1815 (2013.01) [G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/07 (2013.01); G10L 15/16 (2013.01)] | 16 Claims |
|
1. A computer-implemented method comprising:
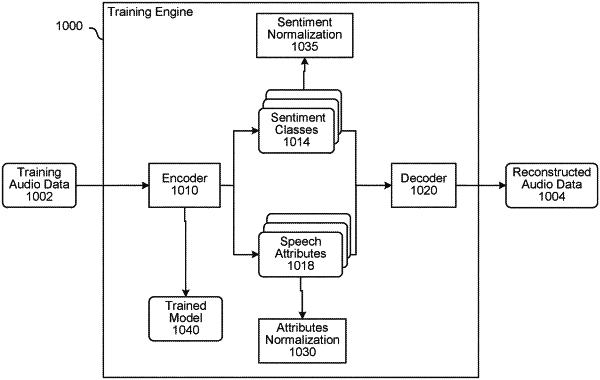
processing, using a first model, first data, representing an original audio signal, to generate first model output data, wherein the first model output data represents at least one sentiment category and at least one attribute of a speaking user;
determining, using the first model output data and a decoder, second data representing an estimation of the original audio signal;
determining third data representing a comparison of the first data and the second data;
generating a first trained model by updating the first model using the at least one attribute of the speaking user and the third data, wherein the first trained model is configured to detect one or more sentiment categories from audio;
after generating the first trained model, receiving input audio data representing speech;
determining, using a stored voice profile associated with a user profile, that a portion of speech corresponding to at least a first portion of the input audio data was spoken by a first user;
using the first trained model, processing the first portion of the input audio data to generate second model output data;
determining, using the second model output data, a first sentiment category corresponding to the first portion of the input audio data; and
associating the first sentiment category with the user profile.
|