| CPC G10L 15/063 (2013.01) [G10L 15/07 (2013.01); G10L 15/20 (2013.01); G10L 17/04 (2013.01); G10L 17/20 (2013.01); G10L 21/0208 (2013.01); G10L 2015/088 (2013.01)] | 12 Claims |
|
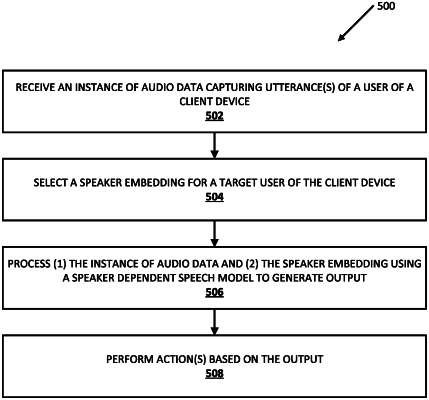
1. A method implemented by one or more processors, the method comprising:
receiving an instance of audio data that captures one or more spoken utterances of a user of a client device, wherein the instance of audio data is captured using one or more microphones of the client device;
determining a speaker embedding corresponding to a target user of the client device, the speaker embedding being generated based on audio data from the target user;
processing the instance of audio data along with the speaker embedding using a speaker dependent voice activity detection model (SD VAD model) to generate output indicating whether the audio data comprises voice activity that is of the target user of the client device, wherein the SD VAD model is personalizable to any user of the client device;
performing one or more actions based on the output, wherein performing the one or more actions based on the output comprises:
determining, based on the output whether the audio data comprises voice activity that is of the target user;
in response to determining the audio data does not comprise voice activity that is of the target user:
determining an additional speaker embedding corresponding to an additional target user of the client device, the additional speaker embedding being generated based on additional audio data from the additional target user; and
processing the instance of audio data, along with the additional speaker embedding and using the SD VAD model, to generate additional output indicating whether the audio data comprises voice activity that is of the additional target user.
|