| CPC G06T 7/74 (2017.01) [G01S 19/54 (2013.01); G06F 18/25 (2023.01); G06N 3/045 (2023.01); G06V 10/764 (2022.01); G06V 10/811 (2022.01); G06V 10/82 (2022.01); G06V 20/13 (2022.01); G06T 2207/10032 (2013.01); G06T 2207/20081 (2013.01)] | 12 Claims |
|
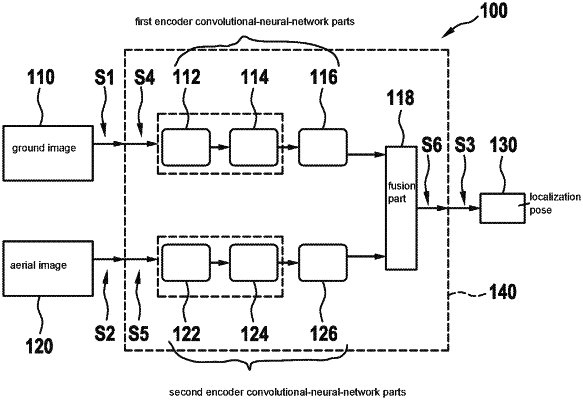
1. A method for determining a localization pose of an at least partially automated mobile platform, the mobile platform being equipped to generate ground images of an area surrounding the mobile platform, and being equipped to receive aerial images of the area surrounding the mobile platform from an aerial-image system, the method comprising the following steps:
providing a digital ground image of the area surrounding the mobile platform;
receiving an aerial image of the area surrounding the mobile platform;
a first trained encoder convolutional-neural-network part of a trained convolutional neural network using the ground image as an input signal to form a first encoding vector at a particular layer of the first trained encoder convolutional-neural-network part;
a second trained encoder convolutional-neural-network part of the trained convolutional neural network using the aerial image as an input signal to form a second encoding vector at a particular layer of the second trained encoder convolutional-neural-network part; and
fusing the first and second encoding vectors by joining the first and second encoding vectors to form neurons of the particular layer of the first trained encoder convolutional-neural-network part and neurons of the particular layer of the second trained encoder convolutional-neural-network part as a combination of input neurons fully connected to neurons of a downstream layer of the convolutional neural network, which generates the localization pose of the mobile platform from the combination of input neurons without the first and second encoding vectors being compared.
|