| CPC G06N 3/08 (2013.01) [G06F 16/583 (2019.01); G06F 40/284 (2020.01); G06N 3/04 (2013.01); G06N 3/084 (2013.01)] | 20 Claims |
|
1. A method comprising:
obtaining a new document, wherein the new document includes a plurality of sequences of words, and, for each sequence of words, a word that follows a last word in the sequence of words in the new document; and
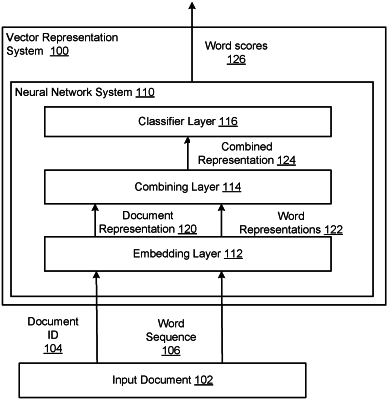
determining a vector representation for the new document using a trained neural network system,
wherein the trained neural network system has been trained on a plurality of unlabeled documents and has been trained to process (i) a document identifier assigned to an input document and (ii) a sequence of words from the input document to generate a respective word score for each word in a pre-determined set of words, wherein the respective word score represents a predicted likelihood that a corresponding word follows a last word in the sequence of words in the input document, and
wherein determining the vector representation for the new document using the trained neural network system comprises, for each iteration step of multiple iteration steps, processing (i) a document identifier assigned to the new document and (ii) one of the plurality of sequences of words by the trained neural network system to determine the vector representation for the new document, wherein the vector representation for the new document is iteratively updated using gradient descent.
|