| CPC G06N 3/08 (2013.01) [G06N 3/008 (2013.01); G06N 3/04 (2013.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01)] | 16 Claims |
|
1. A method comprising:
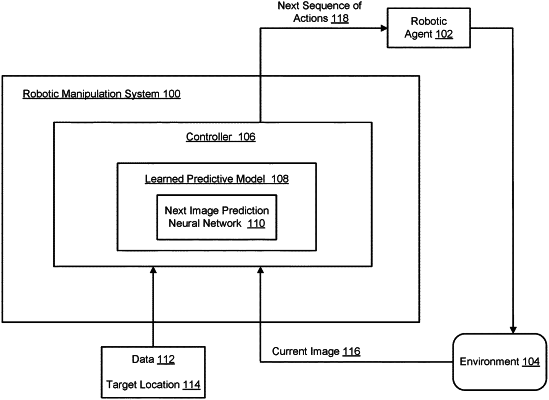
receiving data identifying, for each of one or more objects, a respective target location to which a robotic agent interacting with a real-world environment should move the object; and
causing the robotic agent to move the one or more objects to one or more target locations by repeatedly performing the following:
receiving a current image of a current state of the real-world environment,
determining, from the current image, a next sequence of actions to be performed by the robotic agent using a next image prediction neural network that predicts future images based on a current action and an action to be performed by the robotic agent,
wherein the next sequence is a candidate sequence from a plurality of candidate sequences that, if performed by the robotic agent starting from when the environment is in the current state, would be most likely to result in the one or more objects being moved to the respective target locations, wherein each of the plurality of candidate sequences includes H actions, and
wherein determining the next sequence of actions comprises:
for each of the plurality of candidate sequences:
for a first action in the candidate sequence that includes the H actions, providing as input to the next image prediction neural network the first action and a current image that characterizes a current state of the environment, and processing the first action and the current image using the next image prediction neural network to generate a first next image that is an image of a predicted next state of the environment if the robotic agent first performs the first action when the environment is in the current state, wherein generating the first next image comprises generating a first flow map that gives probabilities that each pixel in the first next image comes from each pixel in the current image,
for each particular action following the first action in the candidate sequence that includes the H actions, providing as input to the next image prediction neural network (i) the particular action and (ii) a preceding next image that was generated by the next image prediction neural network for a preceding action, and processing the particular action and the preceding next image using the next image prediction neural network to generate a new next image that is an image of a predicted next state of the environment if the robotic agent performs the particular action, wherein generating the new next image comprises generating a new flow map that gives probabilities that each pixel in the new next image comes from each pixel in the preceding next image,
obtaining, using the next image prediction neural network, a final flow map for a final next image in the candidate sequence of H actions, the final next image being is an image of a predicted final state of the environment if the robotic agent performs all H actions in the candidate sequence, the final flow map giving probabilities that each pixel in the final next image comes from each pixel in the current image that characterizes the current state of the environment, and
determining, based on the final flow map and the target location, a probability that performance of all H actions in the candidate sequence by the robotic agent would result in the one or more objects being moved to the respective target locations in the final next image, and
selecting, from the plurality of candidate sequences, the candidate sequence with a highest probability as the next sequence of actions, and
directing the robotic agent to perform the next sequence of actions,
wherein the next image prediction neural network is configured to receive as input at least a current image and an input action and to process the input to generate a next image that is an image of a predicted next state of the environment if the robotic agent performs the input action when the environment is in the current state.
|