| CPC G06F 8/75 (2013.01) [G06F 18/22 (2023.01); G06N 5/01 (2023.01); G06N 7/01 (2023.01)] | 14 Claims |
|
1. A computer-implemented method comprising:
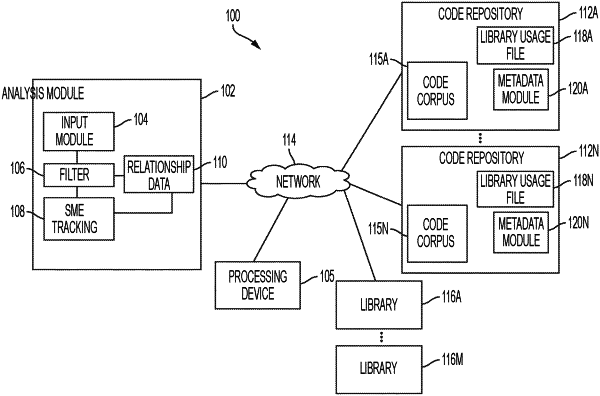
receiving, by a processor, a set of portions of code, the set of portions of code stored as part of a corpus of code in a code repository;
comparing each portion of code and an input type of each portion of code to a ranked list of target input types and key words, each target input type having a ranking based on a user preference;
selecting a portion of code according to a priority of the selected portion of code relative to a remainder of the set, the priority based on the ranking of the input type associated with the selected portion of code;
inputting, by an analysis module, the selected portion of code to a probabilistic data structure to determine whether the selected portion of code is similar to one or more other portions of code in the corpus stored in the code repository;
based on determining, by the probabilistic data structure, that the one or more other portions are similar to the selected portion of code, identifying, by the probabilistic data structure, a number of similar portions of code that were previously input to the probabilistic data structure;
based on the identifying, storing relationship data, in a storage location, that associates the similar portions of code with the selected portion of code;
determining, by a tracking module, one or more subject matter experts (SMEs) associated with the similar portions of code and the selected portion of code based on the relationship data stored in the storage location, and determining correlations between SME data and the relationship data, the SME data including an indication of the determined SMEs, the correlations including an identification of the one or more SMEs associated with each similar portion of code, each SME assigned a ranking based on a number of the similar portions of code associated with the one or more SMEs;
storing the selected portion of code, the SME data and the correlations in the relationship data in the storage location, the relationship data correlating the one or more SMEs to the selected portion of code;
presenting one or more identified SMEs and one or more rankings associated with the one or more identified SMEs for the selected portion of code to a user, based on the relationship data and the one or more rankings stored in the storage location; and
automatically selecting at least one of the one or more identified SMEs based on user input and the one or more rankings associated with the at least one of the one or more identified SMEs.
|