| CPC G06F 40/58 (2020.01) [G06F 40/284 (2020.01); G06F 40/30 (2020.01); G06N 3/08 (2013.01)] | 11 Claims |
|
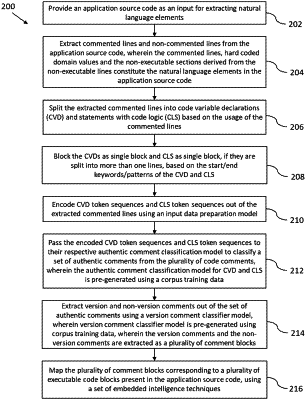
1. A processor implemented method for extracting natural language elements from an application source code, the method comprising:
providing, via one or more hardware interfaces, the application source code as an input for extracting natural language elements, wherein the application source code comprises executable lines and non-executable lines;
extracting, via the one or more hardware interfaces, commented lines and non-commented lines from the application source code, wherein the commented lines, one or more hard-coded domain values and one or more non-executable sections derived from the non-executable lines constitute the natural language elements in the application source code;
splitting, via the one or more hardware interfaces, the extracted commented lines into code variable declarations (CVDs) and statements with code logic (CLS) based on usage of the commented lines;
grouping, via the one or more hardware interfaces, the CVDs and CLS as blocks, if they are split into more than one line, based on start-end keywords or patterns of the CVD and CLS, wherein for CVD data, grouping is done based on the code variable declaration patterns followed by CVD encoding with out of vocabulary handle, and wherein for CLS data grouping is done based on start keywords in code logic statements followed by CLS encoding with out of vocabulary handle;
using, via the one or more hardware interfaces, deep learning networks to understand one or more patterns of the CVD and CLS present in the application source code and segregating a set of authentic comments from the application source code which is commented during at least one of a codefix and an enhancement;
logically grouping, via the one or more hardware interfaces, discrete commented lines of code into a plurality of comment blocks;
encoding, via the one or more hardware interfaces, CVD token sequences and CLS token sequences out of the blocks of CVD and CLS using an input data preparation model;
passing, via the one or more hardware interfaces, the encoded CVD token sequences and CLS token sequences to an authentic comment classification model to classify the set of authentic comments from a plurality of code comments, wherein the authentic comment classification model for CVD and CLS is pre-generated using a corpus training data, wherein the corpus training data for the authentic comment classification model is generated by generating at least one of syntactical token sequences and non-syntactical token sequences, wherein the corpus training data is prepared by removing executable lines of code only once for corpus training data creation and data is prepared for inclusion in the corpus training data by extracting non-executable commented lines of code and wherein the syntactical token sequences and the non-syntactical token sequences are provided as inputs to train the authentic comment classification model, and wherein the executable lines of code contain a combination of multiple syntactical patterns, the multiple syntactical patterns being at least one of CVDs and initiations of CVDs and a set of syntactical patterns which is a combination of code logic statements (CLS);
generating one or more vectors using the syntactical token sequences and the non-syntactical token sequences, the vectors being provided to the authentic comment classification model and wherein the vectors are passed to an embedding layer followed by more than one dense layer and utilizing a specific sequence length and a network structure by the authentic comment classification model, and generating two separate authentic comment neural network classification models for CVDs and CLS;
extracting, via the one or more hardware interfaces, version and non-version comments out of the set of authentic comments using a version comment classifier model, wherein the version comment classifier model is pre-generated using the corpus training data, wherein the version comments and the non-version comments are extracted as the plurality of comment blocks and wherein the set of authentic comments are further used for training and are fed into the version comment classification model to be differentiated as at least one of version comments and non-version comments; and
mapping the plurality of comment blocks corresponding to a plurality of executable code blocks present in the application source code, via the one or more hardware interfaces, using a set of embedded intelligence techniques.
|