| CPC G06F 40/30 (2020.01) [G06F 17/16 (2013.01); G06N 3/04 (2013.01); G06N 5/01 (2023.01); G06N 20/10 (2019.01)] | 20 Claims |
|
1. A method comprising:
obtaining first and second text corpora;
identifying a common vocabulary of the two text corpora;
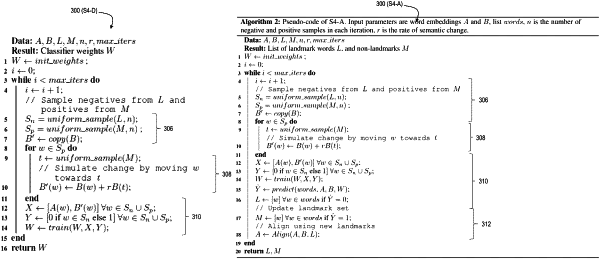
identifying a plurality of landmark words and a plurality of non-landmark words in the common vocabulary;
generating, for each of the words of the common vocabulary, a first word embedding vector in the first text corpus and a second word embedding vector in the second text corpus;
generating, for each word in a random sample of the non-landmark words, an artificially shifted word embedding vector by modifying the first word embedding vector for that word;
training a machine learning classifier to predict whether an artificial shift has been injected for a given word, based on the artificially shifted word embedding vector and the second word embedding vector for the given word; and
predicting semantic shifts for at least a plurality of the words of the common vocabulary by providing the first word embedding vectors and the second word embedding vectors for at least the plurality of the words of the common vocabulary as input to the trained machine learning classifier.
|
|
19. An apparatus comprising:
a memory embodying computer-executable instructions; and
at least one processor, coupled to the memory, and operative by the computer-executable instructions to facilitate a method comprising:
obtaining first and second text corpora;
identifying a common vocabulary of the two text corpora;
identifying a plurality of landmark words and a plurality of non-landmark words in the common vocabulary;
generating, for each of the words of the common vocabulary, a first word embedding vector in the first text corpus and a second word embedding vector in the second text corpus;
generating, for each word in a random sample of the non-landmark words, an artificially shifted word embedding vector by modifying the first word embedding vector for that word;
training a machine learning classifier to predict whether an artificial shift has been injected for a given word, based on the artificially shifted word embedding vector and the second word embedding vector for the given word; and
predicting semantic shifts for at least a plurality of the words of the common vocabulary by providing the first word embedding vectors and the second word embedding vectors for at least the plurality of the words of the common vocabulary as input to the trained machine learning classifier.
|