| CPC G06F 21/577 (2013.01) [G06F 21/31 (2013.01); G06N 3/04 (2013.01); G06N 3/08 (2013.01); G06F 2221/033 (2013.01)] | 20 Claims |
|
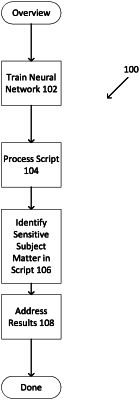
1. A computer-implemented method, comprising:
training a neural network on a corpus of content, wherein the training results in word embeddings for words in the corpus, wherein each of the word embeddings is a numeric vector in a vector or matrix space;
identifying an initial word of interest;
locating a vector that encodes the initial word of interest in the vector or matrix space;
identifying vectors in the vector or matrix space that lie in a specified proximity to the vector for the initial word of interest and identifying words encoded by the identified vectors as additional words of interest, wherein the identifying comprises one of calculating distances between the vector of the initial word of interest and vectors for other encoded words in the vector or matrix space or calculating cosine values between the vector of the initial word of interest and the vectors for the other encoded words in the vector or matrix space and identifying ones of the vectors in the vector or matrix space that have distances or cosine values within a specified range as being in the specified proximity;
performing a security scan of a set of input to identify instances of the initial word of interest and instances of the additional words of interest in the input; and
generating output that specifies the identified instances of the initial word of interest in the set of input and that specifies that the instances of the additional words of interest in the set of input may be of interest.
|