| CPC G06F 21/552 (2013.01) [G06F 16/1734 (2019.01); G06F 40/284 (2020.01); G06F 40/30 (2020.01); G06N 20/00 (2019.01)] | 17 Claims |
|
1. A computer-implemented method, comprising:
performing, by one or more hardware processors with associated memory that implement a context-based anomalous log data identification system:
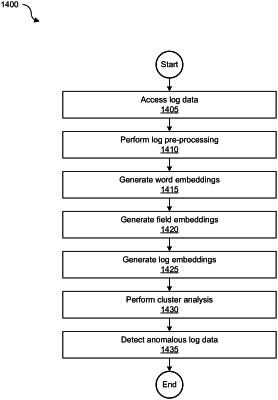
receiving log data comprising a plurality of logs;
generating a context associated training dataset, comprising
splitting a string in a log of the plurality of logs into a plurality of split strings,
generating a context association between each of the plurality of split strings and a unique key that corresponds to the log, and
generating an input/output (I/O) string data batch comprising I/O string data for each split string in the log by training each split string against every other split string of the plurality of split strings in the log; and
training a context-based anomalous log data identification model using the I/O string data batch comprising a list of unique strings in the context associated training dataset and according to a machine learning technique, wherein
the training tunes the context-based anomalous log data identification model to classify or cluster a vector associated with a new string in a new log that is not part of the plurality of logs as anomalous,
training the context-based anomalous log data identification model to perform cluster analysis is based on whether an executable that is part of the process information is a good executable that is part of a bad path, and
the good executable and the bad path are pre-identified based at least on a classifier prior to performing the cluster analysis.
|