| CPC G10L 19/0216 (2013.01) [G06N 3/08 (2013.01); G10L 21/0272 (2013.01); G10L 25/30 (2013.01)] | 20 Claims |
|
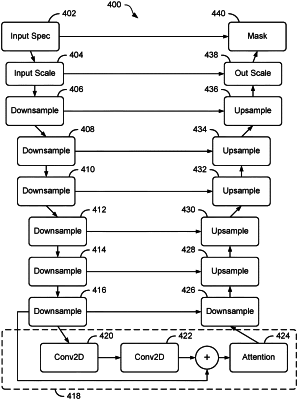
1. A method for decomposing an audio signal, the method comprising:
transforming an original audio file into a complex spectrogram;
splitting the complex spectrogram into K small fragments along the time dimension;
sending each fragment in the K small fragments through one or more convolutional deep neural networks, the convolutional deep neural networks including one or more convolutional layers, the one or more convolutional layers including a subpixel upsample convolutional layer;
producing a sequence of K mask fragments;
concatenating the K mask fragments together in order to form a complete mask which is the same length as the complex spectrogram;
multiplying the complete mask with the complex spectrogram to create a new complex spectrogram; and
transforming the new complex spectrogram into a new audio file.
|