| CPC G10L 13/00 (2013.01) [G10L 13/08 (2013.01); G10L 15/063 (2013.01)] | 20 Claims |
|
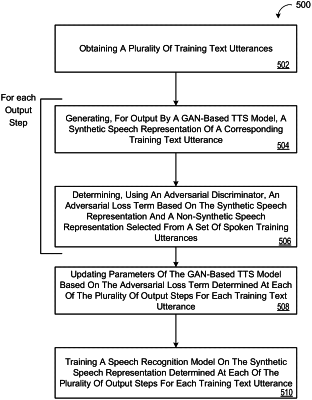
1. A computer-implemented method executed on data processing hardware that causes the data processing hardware to perform operations comprising:
obtaining a spoken training utterance comprising a corresponding transcription paired with a corresponding non-synthetic speech representation of the spoken training utterance;
obtaining an embedding representing speaker characteristics of a speaker that spoke the spoken training utterance;
conditioning the corresponding transcription of the spoken training utterance on the embedding representing the speaker characteristics of the speaker that spoke the spoken training utterance;
generating, as output from a text-to-speech (TTS) model configured to receive the corresponding transcription of the spoken training utterance as input, a synthetic speech representation of the spoken training utterance conditioned on the embedding; and
training a speech recognition model on the non-synthetic speech representation of the spoken training utterance and the synthetic speech representation generated as output from the TTS model.
|