| CPC G06V 10/761 (2022.01) [G06V 10/82 (2022.01)] | 7 Claims |
|
1. An efficient across-camera target re-identification method based on similarity, comprising the following steps:
taking two pictures by two cameras, and subjecting the two pictures to target detection respectively to obtain two groups of corresponding target detection results, wherein one group of the target detection results comprises A targets to be matched, and the other group of the target detection results comprises B targets to be matched; carrying out feature extraction on the two groups of targets to be matched respectively to obtain a feature vector of each target to be matched; pairing different groups of targets to be matched, and calculating similarity scores according to the feature vector to obtain A*B matching pairs and similarity scores thereof, wherein the similarity scores are between [0,1];
taking only a part of the matching pairs with higher similarity scores each time for matching pairs that are not matched by both groups, traversing the part with higher similarity scores in the matching pairs that are not matched by both groups according to an order of the similarity scores thereof from large to small, and outputting the matching pairs traversed and the similarity scores thereof as a matching result, wherein when any target to be matched in a matching pair already appears in the matching result, the target will not be output as the matching result;
wherein when a number of the matching pairs in current matching result does not reach expected K groups, the part with higher similarity scores in the matching pairs that are not matched by both groups is traversed and output again according to the order of the similarity scores from large to small until the matching result reaches an expectation; where 0<K≤min(A,B);
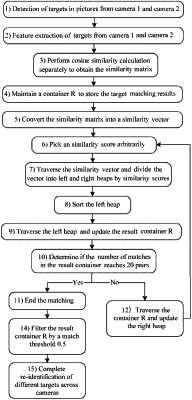
wherein the method comprises the following steps:
1) converting a two-dimensional matrix of the similarity scores of A*B into a one-dimensional vector M, wherein a length of M is A*B, and recording the row and column values of each similarity score which in the original two-dimensional matrix, corresponding to index numbers in a target to be matched of A and B;
2) maintaining a result container R to store a selected matching pairs [i,j,Nij], where Nij is the similarity score, i is the index number of the score Nij A, and j is the index number of the score Nij in B;
3). randomly selecting a similarity score N from the vector M;
4). traversing the similarity scores of the vector M, placing the score greater than N in a left heap H_left, and placing the score less than N in a right heap H_right; wherein the similarity score N is placed in the left heap or the right heap;
5). sorting the left heap H_left to obtain H_left sorted;
6). traversing the heap H_left_sorted in the order from large to small; if i or j of a current index is not in the result container R, obtaining a matching pair [i,j,Nij] and adding the matching pair [i,j,Nij] into the result container R; if i or j of the current index is in the result container R, skipping a current similarity score and continuing traversing;
7). if the number of the matching pairs in the result container R is greater than or equal to K, ending matching to obtain the result container R;
8). if the number of the matching pairs in the result container R is less than K, traversing the result container R, filtering the similarity scores with the same i or the same j in the right heap H_right according to the index in R, and updating the right heap H_right;
taking the filtered right heap H_right as a new vector M, and re-executing steps 3) to 8) until the number of the matching pairs of the result container R is greater than or equal to K, and then outputting the result container R.
|