| CPC G06N 20/00 (2019.01) [G06F 16/906 (2019.01); G06N 5/04 (2013.01); G06N 20/10 (2019.01); G06V 30/224 (2022.01)] | 15 Claims |
|
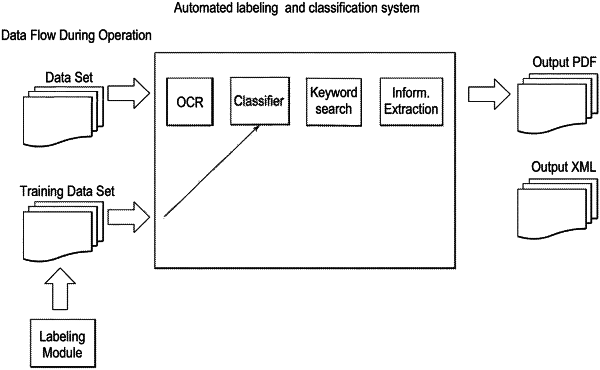
1. A semi- or fully automated, integrated learning and labeling and classification learning system with closed, self-sustaining pattern recognition, labeling and classification operation, comprising:
circuitry configured to
implement a machine learning classifier;
select unclassified data sets and convert the unclassified data sets into an assembly of graphic and text data forming compound data sets to be classified, wherein, by generated feature vectors of training data sets, the machine learning classifier is trained for improving the classification operation of the automated labeling and classification system generically during training as a measure of classification performance, if the automated labeling and classification system is applied to unlabeled and unclassified data sets, and wherein unclassified data sets are classified by applying the machine learning classifier of the automated labeling and classification system to the compound data set of the unclassified data sets;
generate training data sets, wherein for each data set of selected test data sets, a feature vector is generated comprising a plurality of labeled features associated with different selected test data sets;
generate a two-dimensional confusion matrix based on the feature vector of the selected test data sets, wherein a first dimension of the two-dimensional confusion matrix comprises pre-processed labeled features of the feature vectors of the selected test data sets and a second dimension of the two-dimensional confusion matrix comprises classified and verified features of the feature vectors of the selected test data sets by applying the machine learning classifier to the selected test data sets; and
in case an inconsistently or wrongly classified test data set and/or feature of a test data set is detected, assign the inconsistently or wrongly classified test data set and/or feature of the test data set to the training data sets, and generate additional training data sets based on the confusion matrix, which are added to the training data sets for filling in gaps in the training data sets and improving the measurable performance of the automated labeling and classification system, wherein
the circuitry is configured to ignore a given page of a data set if the given page comprises non-relevant text compared to average pages, and the label of a previous page is assigned during inference.
|