| CPC G06F 16/3347 (2019.01) [G06F 16/345 (2019.01)] | 20 Claims |
|
1. A system, comprising:
at least one processor circuit; and
at least one memory that stores program code that, when executed by the at least one processor circuit, performs operations, the operations comprising:
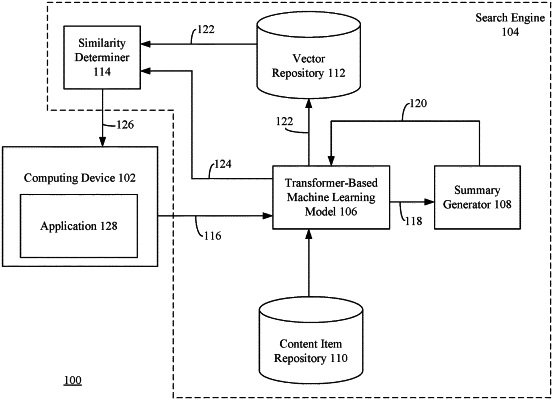
receiving a search query for a first text-based content item in a data set comprising a first plurality of text-based content items;
obtaining a first feature vector representative of the search query;
determining a respective semantic similarity score between the first feature vector and each of a plurality of second feature vectors generated by a transformer-based machine learning model, each of the second feature vectors representative of a machine-generated summarization of a respective first text-based content item of the first plurality of text-based content items, the machine-generated summarization comprising a first plurality of multi-word fragments that are selected from the respective first text-based content item, each machine-generated summarization generated by:
extracting a second plurality of multi-word fragments of text from the respective first text-based content item;
determining importance scores for the second plurality of multi-word fragments based on a similarity matrix;
ranking the second plurality of multi-word fragments based on the importance scores;
selecting a subset of multi-word fragments from the second plurality of multi-word fragments having an N highest importance scores; and
generating the summarization based on sorting the subset; and
providing a search result comprising a subset of the first plurality of text-based content items associated with a respective second feature vector having a semantic similarity score that has a predetermined relationship with a predetermined threshold value.
|