| CPC G06F 16/2456 (2019.01) [G06F 16/2282 (2019.01); G06F 16/248 (2019.01)] | 20 Claims |
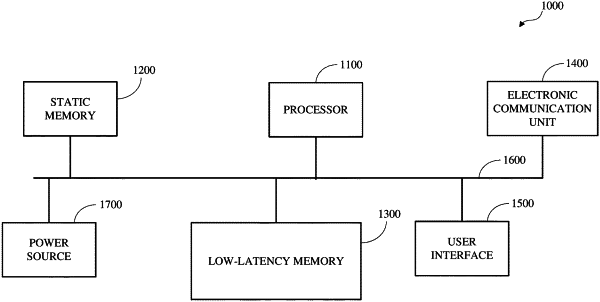
|
1. A method comprising:
in response to receiving data expressing a usage intent with respect to a low-latency data analysis system, wherein the low-latency data analysis system includes a distributed in-memory database:
obtaining, by the distributed in-memory database, a portion of a data query responsive to the data expressing the usage intent, wherein the portion of the data query indicates:
a first table including a first column; and
a limit value;
obtaining, by the distributed in-memory database, results data, wherein obtaining the results data includes:
obtaining filtering criteria;
pseudo-random filtering the first table using the filtering criteria and using, as candidate data, data from the first table, which includes using the first column as a target column;
in response to the pseudo-random filtering of the first table, obtaining the candidate data as intermediate results data; and
obtaining, as the results data, rows from the intermediate results data such that a cardinality of rows of the results data is at most the limit value; and
outputting the results data as responsive to the portion of the data query.
|