| CPC G06F 16/24539 (2019.01) [G06F 16/125 (2019.01); G06F 16/156 (2019.01); G06F 16/162 (2019.01); G06F 16/2455 (2019.01)] | 24 Claims |
|
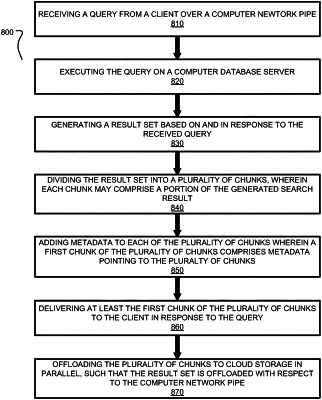
1. A method for managing a persistent query result set in data storage devices, the method comprising:
executing a database query received from a client to generate a result set for the database query and dividing the result set into a plurality of chunks;
as each of the plurality of chunks reaches a size limit, queuing a job to upload the chunk to cloud storage;
adding, by a processor, metadata to each of the plurality of chunks as they are generated, wherein metadata added to a first chunk includes metadata pointing to each of the other chunks in the plurality of chunks and data in a manifest file listing a compressed version of data files and rows contained in the first chunk, and metadata added to each of the other chunks in the plurality of chunks includes a uniform resource locator (URL), a row count of the row indices for that other chunk and a start row for that other chunk, the other chunks in the plurality of chunks being indexed in the cloud storage based on their respective metadata;
providing the first chunk to the client simultaneously with the generation of one or more of the other chunks; and
offloading the other chunks in the plurality of chunks to the cloud storage in parallel, wherein the other chunks are offloaded with respect to a computer network pipe on which the database query was received with the other chunks of the plurality of chunks accessible to the client simultaneously through multiple computer network pipes, each of the multiple computer network pipes comprising a communication channel between the client and the cloud storage, and wherein a first other chunk is obtained using the metadata referencing the other chunks in the plurality of chunks from the first chunk.
|