| CPC G06V 20/41 (2022.01) [G06V 20/46 (2022.01); G06V 20/49 (2022.01)] | 9 Claims |
|
1. A video recognition method, comprising:
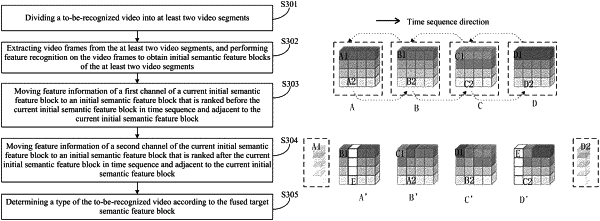
dividing a to-be-recognized video into at least two video segments;
extracting video frames from the at least two video segments, and performing feature recognition on the video frames to obtain initial semantic feature blocks of the at least two video segments;
fusing each of the initial semantic feature blocks, and obtaining a fused target semantic feature block; and
determining, according to the fused target semantic feature block, a type of the to-be-recognized video;
wherein the fusing the obtained initial semantic feature blocks, and obtaining the fused target semantic feature block comprises: fusing, according to a dynamic movement strategy, feature information of different channels of the each of the initial semantic feature blocks, and obtaining the fused target semantic feature block;
wherein the fusing, according to the dynamic movement strategy, the feature information of the different channels of the each of the initial semantic feature blocks comprises:
moving feature information of a first channel of a current initial semantic feature block to an initial semantic feature block that is ranked before the current initial semantic feature block in time sequence and adjacent to the current initial semantic feature block; and
moving feature information of a second channel of the current initial semantic feature block to an initial semantic feature block that is ranked after the current initial semantic feature block in time sequence and adjacent to the current initial semantic feature block.
|