| CPC G06T 7/251 (2017.01) [G06F 18/214 (2023.01); G06N 3/08 (2013.01); G06V 10/774 (2022.01); G06V 20/647 (2022.01); G06V 40/103 (2022.01); G06V 40/23 (2022.01); G06T 2207/10024 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30196 (2013.01)] | 15 Claims |
|
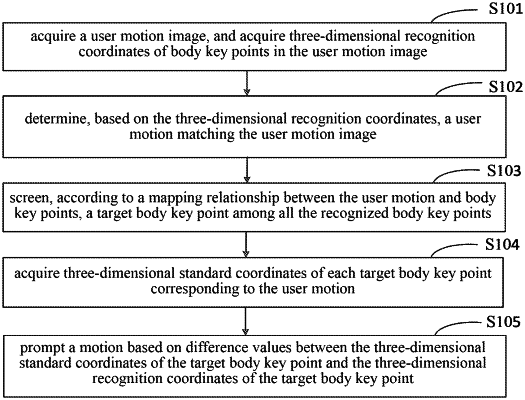
1. A method for prompting a motion, comprising:
acquiring a user motion image, wherein the user motion image is a color image;
inputting the user motion image into a three-dimensional joint point regression model, to obtain a heat map set of body key points and a depth information map set of the body key points output by the three-dimensional joint point regression model;
combining two-dimensional image information of each body key point in the heat map set of the body key points with depth information of each body key point in the depth information map set of the body key points, to obtain three-dimensional recognition coordinates of the body key points;
determining, based on the three-dimensional recognition coordinates, a user motion matching the user motion image;
screening, according to a mapping relationship between the user motion and body key points, a target body key point among all of the recognized body key points;
acquiring three-dimensional standard coordinates of the target body key point corresponding to the user motion; and
prompting a motion based on values of differences between the three-dimensional standard coordinates of the target body key point and the three-dimensional recognition coordinates of the target body key point,
wherein the three-dimensional joint point regression model is obtained by training through:
acquiring sample images with two-dimensional labels and sample images with three-dimensional labels;
training part of channels in an output layer of a basic three-dimensional joint point regression model, with the sample images with the two-dimensional labels as first inputs, and with a set of joint point heat maps corresponding to the two-dimensional labels as first expected outputs; and
training all of the channels in the output layer of the basic three-dimensional joint point regression model to obtain the three-dimensional joint point regression model, with the sample images with three-dimensional labels as second inputs, and with a set of joint point heat maps corresponding to the three-dimensional labels as first parts of second expected outputs, and with a set of joint point depth information maps corresponding to the three-dimensional labels as second parts of the second expected outputs.
|