| CPC G06N 3/084 (2013.01) [G06F 18/2148 (2023.01); G06N 20/00 (2019.01); G06V 10/7747 (2022.01); G06V 10/82 (2022.01); G10L 15/063 (2013.01); G10L 15/12 (2013.01); G10L 15/16 (2013.01); G10L 15/28 (2013.01)] | 22 Claims |
|
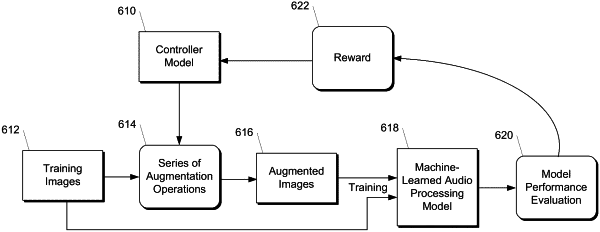
21. One or more non-transitory computer-readable media that collective store instructions that, when executed by one or more processors, cause the one or more processors to perform operations, the operations comprising:
obtaining a plurality of audiographic images that visually represent an audio signal, wherein the plurality of audiographic images correspond to a plurality of times of the audio signal;
generating, using one or more augmentation operations, a plurality of augmented images based on the plurality of audiographic images, wherein the one or more augmentation operations includes:
a time warping operation comprising warping image content of the audiographic image along an axis representative of time,
a frequency masking operation comprising changing pixel values for image content associated with a certain subset of frequencies represented by the audiographic image, or
a time masking operation comprising changing pixel values for image content associated with a certain subset of a time steps represented by the audiographic image;
inputting the plurality of augmented images into a machine-learned audio processing model to generate one or more predictions;
evaluating an objective function that scores the one or more predictions generated by the machine-learned audio processing model; and
modifying respective values of one or more parameters of the machine-learned audio processing model based on the objective function.
|